For this class of problems, the phase transition behavior is
illustrated in Fig. 3. Specifically, this shows the cost to solve the problem with
a simple chronological backtrack search. The cost is given in terms of
the number of search nodes considered until a solution is found. The
minimum cost, for a search that proceeds directly to a solution with no
backtrack is ![]() . The parameter distinguishing underconstrained from
overconstrained problems is the ratio
. The parameter distinguishing underconstrained from
overconstrained problems is the ratio ![]() of the number of nogoods
m at level 2 given by the constraints
to the number of items N.
of the number of nogoods
m at level 2 given by the constraints
to the number of items N.
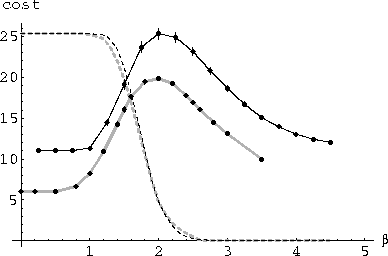
Figure 3: The solid curves show the classical backtrack search cost for randomly generated problems with a prespecified solution as a function of ![]() =m/N for N=10 (gray) and 20 (black) and L=N/2. Here m is the number of nogoods selected at level 2 of the search lattice. The cost is the average number of backtrack steps, starting from the empty set, required to find the first solution to the problem, averaged over 1000 problems. The error bars indicate the standard deviation of this estimate of the average value, and in most cases are smaller than the size of the plotted points. For comparison, the dashed curves show the probability for having a solution in randomly generated problems, ranging from 1 at the left to 0 at the right.
=m/N for N=10 (gray) and 20 (black) and L=N/2. Here m is the number of nogoods selected at level 2 of the search lattice. The cost is the average number of backtrack steps, starting from the empty set, required to find the first solution to the problem, averaged over 1000 problems. The error bars indicate the standard deviation of this estimate of the average value, and in most cases are smaller than the size of the plotted points. For comparison, the dashed curves show the probability for having a solution in randomly generated problems, ranging from 1 at the left to 0 at the right.
Even for these relatively small problems, a peak in the average
search cost is evident. Moreover, this peak is near the transition
region where random problems![]() change from mostly soluble to
mostly insoluble. A simple, but approximate, theoretical value for the
location of the transition is given by the point where the expected
number of solutions is equal to one [50, 53]. Applying this to the class of
problems considered here is straightforward. Specifically, there are
change from mostly soluble to
mostly insoluble. A simple, but approximate, theoretical value for the
location of the transition is given by the point where the expected
number of solutions is equal to one [50, 53]. Applying this to the class of
problems considered here is straightforward. Specifically, there are
![]() complete sets for the problem, as given by
Eq. 1. A particular set
s of size
L will be good, i.e., a solution,
only if none of the nogoods selected for the problem are a subset of
s. Hence the probability it will be a
solution is given by
complete sets for the problem, as given by
Eq. 1. A particular set
s of size
L will be good, i.e., a solution,
only if none of the nogoods selected for the problem are a subset of
s. Hence the probability it will be a
solution is given by
![]()
because there are ![]() sets of size 2 from which to choose the
m nogoods specified directly by the
constraints. The average number of solutions is then just
sets of size 2 from which to choose the
m nogoods specified directly by the
constraints. The average number of solutions is then just
![]() . If we set
. If we set ![]() and
and ![]() , for large N this
becomes
, for large N this
becomes
![]()
where ![]() . The predicted transition
point
. The predicted transition
point![]() is then
given by
is then
given by
![]()
which is ![]() for the case considered here (i.e.,
for the case considered here (i.e., ![]() ). This closely matches the location of the peak in
the search cost for problems with prespecified solution, as shown in
Fig. 3, but is
about 20% larger than the location of the step in
solubility
). This closely matches the location of the peak in
the search cost for problems with prespecified solution, as shown in
Fig. 3, but is
about 20% larger than the location of the step in
solubility![]() . Furthermore, the
theory predicts there is a regime of polynomial average cost for
sufficiently few constraints [28]. This
is determined by the condition that the expected number of goods at each
level in the lattice is monotonically increasing. Repeating the above
argument for smaller levels in the lattice, we find that this condition
holds up to
. Furthermore, the
theory predicts there is a regime of polynomial average cost for
sufficiently few constraints [28]. This
is determined by the condition that the expected number of goods at each
level in the lattice is monotonically increasing. Repeating the above
argument for smaller levels in the lattice, we find that this condition
holds up to
![]()
which is ![]() for
for ![]() .
.
While these estimates are only approximate, they do indicate that
the class of random soluble problems defined here behaves qualitatively
and quantitatively the same with respect to the transition behavior as a
variety of other, perhaps more realistic, problem classes. This close
correspondence with the theory (derived for the limit of large
problems), suggests that we are observing the correct transition
behavior even with these relatively small problems.
Moreover the above approximate theoretical argument suggests
that the average cost of general classical search methods scales
exponentially with the size of the problem over the full range of
![]() . Thus this provides a good test case for the average
behavior of the quantum algorithm. As a final observation, it is
important to obtain a sufficient number of samples, especially near the
transition region. This is because there is considerable variation in
problems near the transition, specifically a highly skewed distribution
in the number of solutions. In this region, most problems have few
solutions but a few have extremely many: enough in fact to give a
substantial contribution to the average number of solutions even though
such problems are quite rare.
. Thus this provides a good test case for the average
behavior of the quantum algorithm. As a final observation, it is
important to obtain a sufficient number of samples, especially near the
transition region. This is because there is considerable variation in
problems near the transition, specifically a highly skewed distribution
in the number of solutions. In this region, most problems have few
solutions but a few have extremely many: enough in fact to give a
substantial contribution to the average number of solutions even though
such problems are quite rare.