In this section we want to describe the constraints and principles which are important for our system design. As we outlined and motivated in the introduction, the screening approach is a flat, robust, learned analysis of spoken language based on category sequences (called flat representations) at various syntactic and semantic levels. In order to test this screening approach, we designed and implemented the hybrid connectionist SCREEN system which processes spontaneously spoken language by using learned connectionist flat representations. Here we summarize our main requirements in order to motivate the specific system design which will be explained in the subsequent subsections.
We consider learning to be extremely important for spoken-language analysis for several reasons. Learning reduces knowledge acquisition and increases portability, particularly in spoken-language analysis, where the underlying rules and regularities are difficult to formulate and often not reliable. Furthermore, in some cases, inductive learning may detect unknown implicit regularities. We want to use connectionist learning in simple recurrent networks rather than other forms of learning (e.g., decision trees) primarily because of the inherent fault-tolerance of connectionist networks, but also because knowledge about the sequence of words and categories can be learned in simple recurrent networks.
Fault-tolerance for often occurring language errors should be reflected in the system design. We do this for the commonly occurring errors (interjections, pauses, word repairs, phrase repairs). However, fault-tolerance cannot go so far as to try to model each class of occurring errors. The number of potentially occurring errors and unpredictable constructions is far too large. In SCREEN, we want to incorporate explicit fault-tolerance by using specific modules for correction as well as implicit fault-tolerance by using connectionist network techniques which are inherently fault-tolerant due to their support of similarity-based processing. In fact, even if a word is completely unknown, recurrent networks can use an empty input and may even assign the correct category if there is sufficient previous context.
Flat representations, as motivated in Sections 1 and 3, may support a robust spoken-language analysis. However, flat connectionist representations do not provide the full recursive power of arbitrary syntactic or semantic symbolic knowledge structures. In contrast to context-free parsers, flat representations provide a better basis for robust processing and automatic knowledge acquisition by inductive learning. However, it can also be argued that the use of potentially unrestricted recursion of well-known context-free grammar parsers provides a computational model with more recursive power than humans have in order to understand language. In order to better support robustness, we want to use flat representations for spontaneous language analysis.
Incremental processing of speech, syntax, semantics and dialog processing in parallel allows us to start the language analysis in parallel before the speech recognizer has finished its analysis. This incremental processing has the advantage of providing analysis results at a very early stage. For example, syntactic and semantic processing occur in parallel only slightly behind speech processing. When analyzing spoken language based on speech recognizer output, we want to consider many competing paths of word hypothesis sequences in parallel.
With respect to hybrid representations, we examine a hybrid connectionist architecture using connectionist networks where they are useful but we also want to use symbolic processing wherever necessary. Symbolic processing can be very useful for the complex control in a large system. On the other hand for learning robust analysis, we use feedforward and simple recurrent networks in many modules and try to use rather homogeneous, supervised networks.
SCREEN has a parallel integrated hybrid architecture (Wermter, 1994) which has various main properties:
We will now give an overview of the various parts in SCREEN (see Figure 6). The important output consists of flat syntactic and semantic category representations based on the input of incrementally recognized parallel word hypotheses. A speech recognizer generates many incorrect word hypotheses over time, and even correctly recognized speech can contain many errors introduced by humans. A flat representation is used since it is more fault-tolerant and robust than, for instance, a context-free tree representation since a tree representation requires many more decisions than a flat representation.
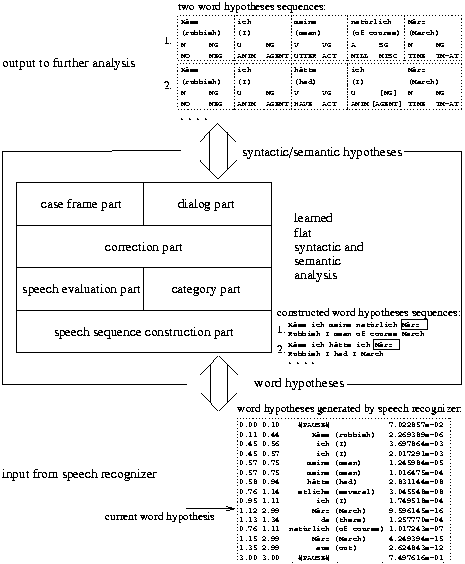 Figure 6: Overview of SCREEN |
Each module in the system, for instance the disambiguation of abstract syntactic categories, contains a connectionist network or a symbolic program. The integration of symbolic and connectionist representations occurs as an encapsulation of symbolic and connectionist processes at the module level. Connectionist networks are embedded in symbolic modules which can communicate with each other via messages.
However, what are the essential parts needed for our purposes of learning spoken-language analysis and why? Starting from the output of individual word hypotheses of a speech recognizer, we first need a component which receives an incremental stream of individual parallel word hypotheses and produces an incremental stream of word hypothesis sequences (see Figure 6). We call this part the speech sequence construction part. It is needed for transforming parallel overlapping individual word hypotheses to word hypothesis sequences. These word hypothesis sequences have a different quality and the goal is to find and work with the best word hypothesis sequences. Therefore we need a speech evaluation part which can combine speech-related plausibilities with syntactic and semantic plausibilities in order to restrict the attention to the best found word hypothesis sequences.
Furthermore, we need a part which analyzes the best found word hypothesis sequences according to their flat syntactic and semantic representation. The category part receives a stream of current word hypothesis sequences. Two such word hypothesis sequences are shown in Figure 6. This part provides the interpretation of a word hypothesis sequence with its basic syntactic categories, abstract syntactic categories, basic semantic categories, and abstract semantic categories. That is, each word hypothesis sequence is assigned four graded preferences for four word categories.
Human speech analyzed by a speech recognizer may contain many errors. So the question arises to what extent we want to consider these errors. An analysis of several hundred transcripts and speech recognizer outputs revealed that there are some errors which occur often and regularly. These are interjections, pauses, word repairs, and phrase repairs. Therefore we designed a correction part which receives hypotheses about words and deals with most frequently occurring errors in spoken language explicitly.
These parts outlined so far build the center of the integration of speech-related and language-related knowledge in a flat fault-tolerant learning architecture, and therefore we will focus on these parts in this paper. However, if we want to process complete dialog turns which can contain several individual utterances we need to know where a certain utterance starts and which constituents belong to this utterance. This task is performed by a case frame part which fills a frame incrementally and segments a speaker's turn into utterances.
The long-term perspective of SCREEN is to provide an analysis for tasks such as spoken utterance translation or information extraction. Besides the syntactic and semantic analysis of an utterance, the intended dialog acts convey important additional knowledge. Therefore, a dialog part is needed for assigning dialog acts to utterances, for instance if an utterance is a request or suggestion. In fact, we have already fully implemented the case frame part and the dialog part for all our utterances. However, we will not describe the details of these two parts in this paper since they have been described elsewhere (Wermter & Löchel, 1996).
Learning in SCREEN is based on concepts of supervised learning as for instance in feedforward networks (Rumelhart et al., 1986), simple recurrent networks (Elman, 1990) and more general recurrent plausibility networks (Wermter, 1995). In general, recurrent plausibility networks allow an arbitrary number of context and hidden layers for considering long distance dependencies. However, for the many network modules in SCREEN we attempted to keep the individual networks simple and homogeneous. Therefore, in our first version described here we used only variations of feedforward networks (Rumelhart et al., 1986) and simple recurrent networks (Elman, 1990). Due to their greater potential for sequential context representations, recurrent plausibility networks might provide improvements and optimizations of simple recurrent networks. However, for now we are primarily interested in an overall real-world hybrid connectionist architecture SCREEN rather than the optimization of single networks. In the following description we will give detailed examples of the individual networks.
After we motivated the various parts in SCREEN, we will now give a more detailed description of the architecture of SCREEN with respect to the modules for flat syntactic and semantic analysis of word hypothesis sequences. Therefore, we will focus on the speech related parts, the categorization part and correction part. Figure 7 shows a more detailed overview of these parts. The basic data flow is shown with arrows. Many modules generate hypotheses which are used in subsequent modules at a higher level. These hypotheses are illustrated with rising arrows. In some modules, the output contains local predictive hypotheses (sometimes called local top-down hypotheses) which are used again in modules at a lower level. These hypotheses are illustrated with falling arrows. Local predictive hypotheses are used in the correction part to eliminate4 repaired utterance parts and in the speech evaluation part to eliminate syntactically or semantically implausible word hypothesis sequences. In some cases where arrows would have been too complex we have used numbers to illustrate the data flow between individual modules.
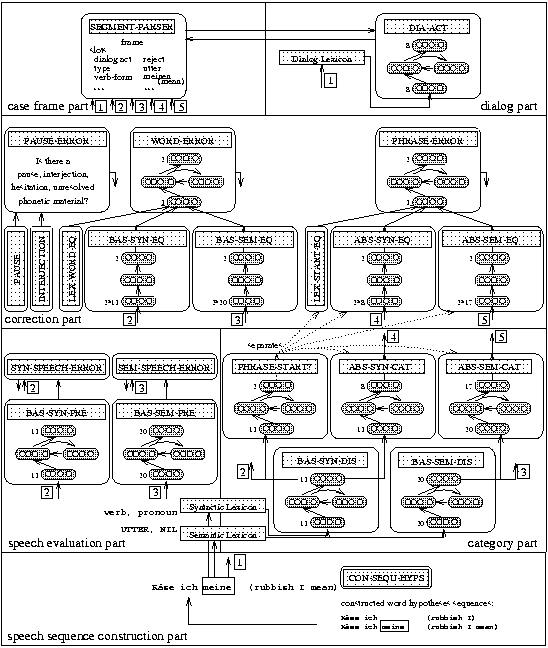 | |
| Figure 7: | More detailed overview of SCREEN. The abbreviations and functionality of the modules are described in the text. |
The speech sequence construction part receives a stream of parallel word hypotheses and generates a stream of word hypothesis sequences within the module CON-SEQU-HYPS at the bottom of Figure 7. Based on the current word hypotheses many word hypothesis sequences may be possible. In some cases we can reduce the number of current word hypotheses, e.g., if we know that time has passed so far that a specific word hypothesis sequence cannot be extended anymore at the time of the current word hypothesis. In this case we can eliminate this sequence since only word hypothesis sequences which could reach the end of the sentence are candidates for a successful speech interpretation.
Furthermore, we can use the speech plausibility values of the individual word hypothesis to determine the speech plausibility of a word hypothesis sequence. By using only some of the best word hypothesis sequences we can reduce the large space of possible sequences. The generated stream of word hypothesis sequences is similar to a set of partial N-best representations which are generated and pruned incrementally during speech analysis rather than at the end of the speech analysis process.
The speech evaluation part computes plausibilities based on syntactic and semantic knowledge in order to evaluate word hypothesis sequences. This part contains the modules for the detection of speech-related errors. Currently, the performance of speech recognizers for spontaneously spoken speaker-independent speech is in general still far from perfect. Typically, many word hypotheses are generated for a certain signal5. Therefore, many hypothesized words produced by a speech recognizer are incorrect and the speech confidence value for a word hypothesis alone does not provide enough evidence for finding the desired string for a signal. Therefore the goal of the speech evaluation part is to provide a preference for filtering out unlikely word hypothesis sequences. SYN-SPEECH-ERROR and SEM-SPEECH-ERROR are two modules which decide if the current word hypothesis is a syntactically (semantically) plausible extension of the current word hypothesis sequence. The syntactic (semantic) plausibility is based on a basic syntactic (semantic) category disambiguation and prediction.
In summary, each word hypothesis sequence has an acoustic confidence based on the speech recognizer, a syntactic confidence based on SYN-SPEECH-ERROR, and a semantic confidence based on SEM-SPEECH-ERROR. These three values are integrated and weighted equally6 to determine the best word hypothesis sequences. That way, these two modules can act as an evaluator for the speech recognizer as well as a filter for the language processing part.
In statistical models for speech recognition, bigram or trigram models are used as language models for filtering out the best possible hypotheses. We used simple recurrent networks since these networks performed slightly better than a bigram and a trigram model which had been implemented for comparison (Sauerland, 1996). Later in Section 6.1 we will also show a detailed comparison of simple recurrent networks and n-gram models (for n = 1,...,5). The reason for this better performance is the internal representation of a simple recurrent network which does not restrict the covered context to a fixed number of two or three words but has the potential to learn the required context that is needed.
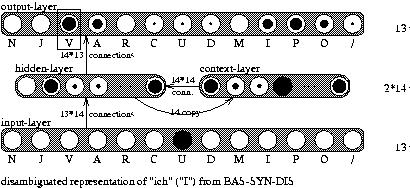 | |
| Figure 8: | Network architecture for the syntactic prediction in the speech evaluation part (BAS-SYN-PRE). The abbreviations are explained in Table 1. |
The knowledge for the syntactic and semantic plausibility is provided by the prediction networks (BAS-SYN-PRE and BAS-SEM-PRE) of the speech evaluation part and the disambiguation networks (BAS-SYN-DIS and BAS-SEM-DIS) of the categorization part. As an example, we show the network for BAS-SYN-PRE in Figure 8. The previous basic syntactic category of the currently considered word hypothesis sequence is input to the network. In our example ``ich'' (``I'') from the word hypothesis sequence ``Käse ich meine'' (``Rubbish I mean'') is found to be a pronoun (U). Therefore, the syntactic category representation for ``ich'' (``I'') contains a ``1'' for the pronoun (U) category. All other categories receive a ``0''.
The input to this network consists of 13 units for our 13 categories. The output of the network has the same size. Each unit of the vector represents a plausibility for the predicted basic syntax category of the last word in the current word hypothesis sequence. The plausibility of the unit representing the desired basic syntactic category (found by BAS-SYN-DIS) is taken as syntactic plausibility for the currently considered word hypothesis sequence by SYN-SPEECH-ERROR. In this example ``meine'' (``mean'') is found to be a verb (V). Therefore the plausibility for a verb (V) will be taken as syntax plausibility (selection marked by a box in the output-layer of BAS-SYN-PRE in Figure 8).
In summary, the syntactic (semantic) plausibility of a word hypothesis sequence is evaluated by the degree of agreement between the disambiguated syntactic (semantic) category of the current word and the predicted syntactic (semantic) category of the previous word. Since decisions about the current state of a whole sequence have to be made, the preceding context is represented by copying the hidden layer for the current word to the context layer for the next word based on an SRN network structure (Elman, 1990). All connections in the network are n:m connections except for the connections between the hidden layer and the context layer which are simply used to copy and store the internal preceding state in the context layer for later processing when the next word comes in. In general, the speech evaluation part provides a ranking of the current word hypothesis sequences by the equally weighted combination of acoustic, syntactic, and semantic plausibility.
The module BAS-SYN-DIS performs a basic syntactic disambiguation (see Figure 9). Input to this module is a sequence of potentially ambiguous syntactic word representations, one for each word of an utterance at a time. Then this module disambiguates the syntactic category representation according to the syntactic possibilities and the previous context. The output is a preference for a disambiguated syntactic category. This syntactic disambiguation task is learned in a simple recurrent network. Input and output of the network are the ambiguous and disambiguated syntactic category representations. In Figure 9 we show an example input representation for ``meine'' (``mean'', ``my'') which can be a verb and a pronoun. However, in the sequence ``Ich meine'' (``I mean''), ``meine'' can only be a verb and therefore the network receives the disambiguated verb category representation alone.
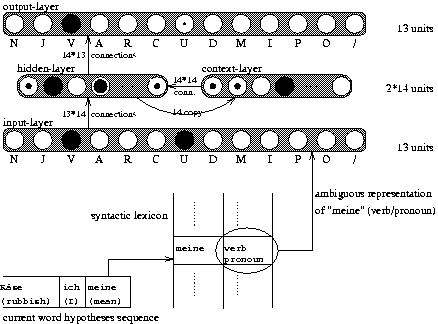 | |
| Figure 9: | Network architecture for the basic syntactic disambiguation (BAS-SYN-DIS). The abbreviations are explained in Table 1. |
The module BAS-SEM-DIS is similar to the module BAS-SYN-DIS but instead of receiving a potentially ambiguous syntactic category input and producing a disambiguated syntactic category output, the module BAS-SEM-DIS receives a semantic category representation from the lexicon and provides a disambiguated semantic category representation output. This semantic disambiguation is learned in a simple recurrent network which provides the mapping from the ambiguous semantic word representation to the disambiguated semantic word representation. Both modules BAS-SYN-DIS and BAS-SEM-DIS provide this disambiguation so that subsequent tasks like the association of abstract categories and the test of category equality for word error detection is possible.
The module ABS-SYN-CAT supplies the mapping from disambiguated basic syntactic category representations to the abstract syntactic category representations (see Figure 10). This module provides the abstract syntactic categorization and it is realized with a simple recurrent network. This module is important for providing a flat abstract interpretation of an utterance and for preparing input for the detection of phrase errors. Figure 10 shows that the disambiguated basic syntactic representation of ``meine'' (``mean'') as a verb - and a very small preference for a pronoun - is mapped to the verb group category at the higher abstract syntactic category representation. Based on the number of our basic and abstract syntactic categories there are 13 input units for the basic syntactic categories and 8 output units for the abstract syntactic categories.
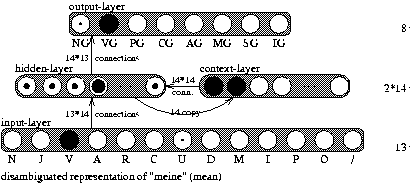 | |
| Figure 10: | Network architecture for the abstract syntactic categorization (ABS-SYN-CAT). The abbreviations are explained in Table 2. |
The module ABS-SEM-CAT is a parallel module to ABS-SYN-CAT but uses basic semantic category representations as input and abstract semantic category representations as output. Similar to the previous modules, we also used a simple recurrent network to learn this mapping and to represent the sequential context. The input to the network is the basic semantic category representation for the word, and the output is an abstract category preference.
These described four networks provide the basis for the fault-tolerant flat analysis and the detection of errors. Furthermore, there is the module PHRASE-START for distinguishing abstract categories. The task of this module is to indicate the boundaries of subsequent abstract categories with a delimiter. We use these boundaries to determine the abstract syntactic and abstract semantic category of a phrase7. Earlier experiments had provided support to take the abstract syntactic category of the first word in a phrase as the final abstract syntactic category of a phrase, since phrase starts (e.g., prepositions) are good indicators for abstract syntactic categories (Wermter & Löchel, 1994). On the other hand, earlier experiments supported to take the abstract semantic category of the last word of a phrase as the final abstract semantic category of a phrase, since phrase ends (e.g., nouns) are good indicators for abstract semantic categories (Wermter & Peters, 1994). Furthermore, the phrase start gives us an opportunity to distinguish two equal subsequent abstract categories of two phrases. For instance, if we have a phrase like ``in Hamburg on Monday'' we have to know where the border exists between the first and the second prepositional phrase.
The correction part contains modules for detecting pauses, interjections, as well as repetitions and repairs of words and phrases (see Figure 7). The modules for detecting pause errors are PAUSE-ERROR, PAUSE and INTERJECTION. The modules PAUSE and INTERJECTION receive the currently processed word and detect the potential occurrence of a pause and interjection, respectively. The output of these modules is input for the module PAUSE-ERROR. As soon as a pause or interjection has been detected, the word is marked as deleted and therefore virtually eliminated from the input stream8. An elimination of interjections and pauses is desired - for instance in a speech translation task - in order to provide an interpretation with as few errors as possible. Since these three modules are basically occurrence tests they have been realized with symbolic representations.
The second main cluster of modules in the correction part are the modules which are responsible for the detection of word-related errors. Then, word repairs as in ``Am sechsten April bin ich ich'' (``on sixth April am I I'') or ``Wir haben ein Termin Treffen'' (``We have a date meeting'') can be dealt with. There are certain preferences for finding repetitions and repairs at the word level. Among these preferences there is the lexical equality of two subsequent words (symbolic module LEX-WORD-EQ), the equality of two basic syntactic category representations (connectionist module BAS-SYN-EQ), and the equality of the basic semantic categories of two words (connectionist module BAS-SEM-EQ). As an example for the three modules, we show the test for syntactic equality (BAS-SYN-EQ) in Figure 11.
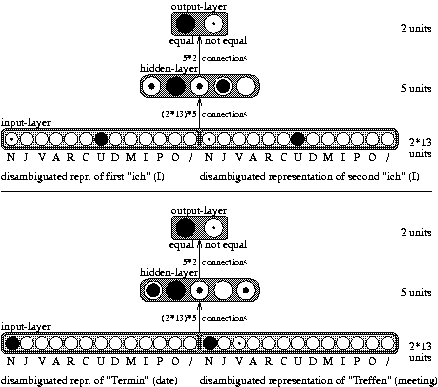 | |
| Figure 11: | Network architecture for the equality of basic syntactic category representation (BAS-SYN-EQ). The abbreviations are explained in Table 1. |
Two output units for plausible/implausible outcome have been used here since the network with two output units gave consistently better results compared with a network with only one output unit (with 1 for plausible and 0 for implausible). The reason why the network with two output units performed better is the separation of the weights for plausible and implausible in the hidden-output layer. In order to receive a single value, the two output values are integrated according to the formula: unit1 * (1.0 - unit2). Then, the output of all three equality modules is a value between 0 and 1 where 1 represents equality and 0 represents inequality. Although a single such preference may not be sufficient, the common influence provides a reasonable basis for detecting word repairs and word repetitions in the module WORD-ERROR. Then, word repairs and repetitions are eliminated from the original utterance. Since the modules for word-related errors are based on two representations of two subsequent input words and since context can only play a minor role, we use feedforward networks for these modules. On the other hand, the simple test on lexical equality of the two words in LEX-WORD-EQ is represented more effectively using symbolic representation.
The third main cluster in the correction part consists of modules for the detection and correction of phrase errors. An example for a phrase error is: ``Wir brauchen den früheren Termin den späteren Termin'' (``We need the earlier date the later date''). There are preferences for phrase errors if the lexical start of two subsequent phrases is equal, if the abstract syntactic categories are equal and if the abstract semantic categories are equal. For these three preferences we have the modules LEX-START-EQ, ABS-SYN-EQ and ABS-SEM-EQ. All these modules receive two input representations of two corresponding words from two phrases, LEX-START-EQ receives two lexical words, ABS-SYN-EQ two abstract syntactic category representations, and ABS-SEM-EQ two abstract semantic category representations. The output of these three modules is a value toward 1 for equality and toward 0 otherwise. These values are input to the module PHRASE-ERROR which finally decides whether a phrase is replaced by another phrase. As the lexical equality of two words is a discrete test, we have implemented LEX-START-EQ symbolically, while the other preferences for a phrase error have been implemented as feedforward networks.