Recently the fields of speech processing as well as language processing have both seen efforts to examine the possibility of integrating speech and language processing (von Hahn & Pyka, 1992; Jurafsky et al., 1994b; Waibel et al., 1992; Ward, 1994; Menzel, 1994; Geutner et al., 1996; Wermter et al., 1996). While new and large speech and language corpora are being developed rapidly, new techniques have to be examined which particularly support properties of both speech and language processing. Although there have been quite a few approaches to spoken-language analysis (Mellish, 1989; Young et al., 1989; Hauenstein & Weber, 1994; Ward, 1994), they have not emphasized learning a syntactic and semantic analysis of spoken language using a hybrid connectionist1 architecture which is the topic of this paper and our goal in SCREEN2. However, learning is important for the reduction of knowledge acquisition, for automatic system adaptation, and for increasing the system portability for new domains. Different from most previous approaches, in this paper we demonstrate that hybrid connectionist learning techniques can be used for providing a robust flat analysis of faulty spoken language.
Processing spoken language is very different from processing written language, and successful techniques for text processing may not be useful for spoken-language processing. Processing spoken language is less constrained, contains more errors and less strict regularities than written language. Errors occur on all levels of spoken-language processing. For instance, acoustic errors, repetitions, false starts and repairs are prominent in spontaneously spoken language. Furthermore, incorrectly analyzed words, unforeseen grammatical and semantic constructions occur very often in spoken language. In order to deal with these important problems for ``real-world'' language analysis, robust processing is necessary. Therefore we cannot expect that existing techniques like context-free tree representations which have been proven to work for written language can simply be transferred to spoken language.
For instance, consider that a speech recognizer has produced the correct German sentence hypothesis ``Ich meine natürlich März'' (English translation: ``I mean of_course March''). Standard techniques from text processing - like chart parsers and context-free grammars - may be able to produce deeply structured tree representations for many correct sentences as shown in Figure 1.
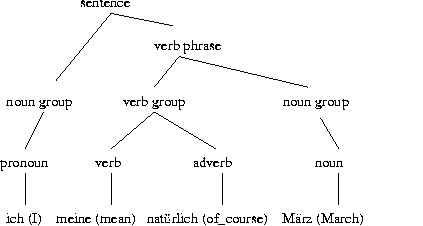 Figure 1: Tree representation for a correctly recognized sentence |
However, currently speech recognizers are still far from perfect and produce many word errors so that it is not possible to rely on a perfect sentence hypothesis. Therefore, incorrect variations like ``Ich meine ich März'' (``I mean I March''), ``Ich hätte ich März'' (``I had I March'') and ``Ich Ich meine März'' (``I I mean March'') have to be analyzed. However, in context-free grammars a single syntactic or semantic category error may prevent that a complete tree can be built, and standard top-down chart parsers may fail completely. However, suboptimal sentence hypotheses have to be analyzed since sometimes such sentence hypotheses are the best possible output produced by a speech recognizer. Furthermore, a lot of the content can be extracted even from partially incorrect sentence hypotheses. For instance, from ``I had I March'' it is plausible that an agent ``I'' said something about the time ``March''. Therefore, a robust analysis should be able to analyze such sentence hypotheses and ideally should not break for any input.
For such examples of incorrect variations of sentence hypotheses, an in-depth structured syntactic and semantic representation is not advantageous since more arbitrary word order and spontaneous errors make it often impossible to determine a desired deep highly structured representation. Furthermore, a deep highly structured representation may have many more restrictions than appropriate for spontaneously spoken language. However, and maybe even more important, for certain tasks it is not necessary to perform an in-depth analysis. While, for instance, inferences about story understanding require an in-depth understanding (Dyer, 1983), tasks like information extraction from spoken language do not need much of an in-depth analysis. For instance, if the output of our parser were to be used for translating a speech recognizer sentence hypothesis ``Eh ich meine eh ich März'' (``Eh I mean eh I March''), it may be sufficient to extract that an agent (``I'') uttered (``mean'') a time (``March''). In contrast to a deeply structured representation, our screening approach aims at reaching a flat but robust representation of spoken language. A screening approach is a shallow flat analysis based on category sequences (called flat representations) at various syntactic and semantic levels.
A flat representation structures an utterance U with words w1 to wn according to the syntactic and semantic properties of the words in their contexts, e.g., according to a sequence of basic or abstract syntactic categories. For instance, the phrase ``a meeting in London'' can be described as a flat representation ``determiner noun preposition noun'' at a basic syntactic level and as a flat representation ``noun-group noun-group prepositional-group prepositional-group'' at an abstract syntactic level. Similar flat representations can be used for semantic categories, dialog act categories, etc.
Figure 2 gives an example for a flat representation for a correct sentence hypothesis ``Käse ich meine natürlich März'' (``Rubbish I mean of_course March''). The first line shows the sentence, the second its literal translation. The third line describes the basic syntactic category of each word, the fourth line shows the basic semantic category. The last two lines illustrate the syntactic and semantic categories at the phrase level.
Figure 3: Utterance with its flat representation |
Figure 3 gives an example for a flat representation for the incorrect sentence hypothesis ``Käse ich hätte ich März'' (``Rubbish I had I March''). A parser for spoken language should be able to process such sentence hypotheses as far as possible, and we use flat representations to support the necessary robustness. In our example, the analysis should at least provide that an animate agent and noun group (``I'') made some statement about a specific time and noun group (``March''). Flat representations have the potential to support robustness better since they have only a minimal sequential structure, and even if an error occurs the whole representation can still be built. In contrast, in standard tree-structured representations many more decisions have to be made to construct a deeply structured representation, and therefore there are more possibilities to make incorrect decisions, in particular with noisy spontaneously spoken language. So we chose flat representations rather than highly structured representations because of the desired robustness against mistakes in speech/language systems.
Robust spoken-language analysis using flat representations could be pursued in different approaches. Therefore we want to motivate why we use a hybrid connectionist approach, which uses connectionist networks as far as possible but does not rule out the use of symbolic knowledge. So why do we use connectionist networks?
Most important, due to their distributed fault tolerance, connectionist networks support robustness (Rumelhart et al., 1986; Sun, 1994) but connectionist networks also have a number of other properties which are relevant for our spoken-language analysis. For instance, connectionist networks are well known for their learning and generalization capabilities. Learning capabilities allow to induce regularities directly from examples. If the training examples are representative for the task, the noisy robust processing should be supported by inductive connectionist learning.
Furthermore, a hybrid connectionist architecture has the property that different knowledge sources can take advantage of the learning and generalization capabilities of connectionist networks. On the other hand, other knowledge - task or control knowledge - for which rules are known can be represented directly in symbolic representations. Since humans apparently do symbolic inferencing based on real neural networks, abstract models as symbolic representations and connectionist networks have the additional potential to shed some light on human language processing capabilities. In this respect, our approach also differs from other candidates for robust processing, like statistical taggers or statistical n-grams. These statistical techniques can be used for robust analysis (Charniak, 1993) but statistical techniques like n-grams do not relate to the human cognitive language capabilities while simple recurrent connectionist networks have more relationships to the human cognitive language capabilities (Elman, 1990).
SCREEN is a new hybrid connectionist system developed for the examination of flat syntactic and semantic analysis of spoken language. In earlier work we have explored a flat scanning understanding for written texts (Wermter, 1995; Wermter & Löchel, 1994; Wermter & Peters, 1994). Based on this experience we started a completely new project SCREEN to explore a learned fault-tolerant flat analysis for spontaneously spoken-language processing. After preliminary successful case studies with transcripts we have developed the SCREEN system for using knowledge generated from a speech recognizer. In previous work, we gave a brief summary of SCREEN with a specific focus on segmentation parsing and dialog act processing (Wermter & Weber, 1996a). In this paper, we focus on a detailed description of SCREEN's architecture, the flat syntactic and semantic analysis, the interaction with a speech recognizer, and a detailed evaluation analysis of the robustness under the influence of noisy or incomplete input.
The paper is structured as follows. In Section 2 we provide a more detailed description of examples of noise in spoken language. Noise can be introduced by the human speaker but also by the speech recognizer. Noise in spoken-language analysis motivates the flat representations whose categories are described in Section 3. All basic and abstract categories at the syntactic and semantic level are explained in this section. In Section 4 we motivate and explain the design of the SCREEN architecture. After a brief functional overview, we show the overall architecture and explain details of individual modules up to the connectionist network level. In order to demonstrate the behavior of this flat analysis of spoken language we provide various detailed examples in Section 5. Using several representative sentences we walk the reader through a detailed step-by-step analysis. After the behavior of the system has been explained, we provide the overall analysis of the SCREEN system in Section 6. We evaluate the system's individual networks, compare the performance of simple recurrent networks with statistical n-gram techniques, and show that simple recurrent networks performed better than 1-5 grams for syntactic and semantic prediction. Furthermore we provide an overall system evaluation, examine the overall performance under the influence of additional noise, and supply results from a transfer to a different second domain. Finally we compare our approach to other approaches and conclude that flat representations based on connectionist networks provide a robust learned spoken-language analysis.
We want to point out that this paper does not make an argument against deeply structured symbolic representations for language processing in general. Usually, if a deeply structured representation can be built, of course due to the additional knowledge it contains, its potential for more powerful relationships and interpretations will be greater than that of a flat representation. For instance, in-depth analysis is required for tasks like making detailed planning inferences while reading text stories. However, our screening approach is motivated based on noisy spoken-language analysis. For noisy spoken-language analysis, flat representations support robustness, and connectionist networks are effective for providing such robustness due to their learned fault-tolerance. This is a main contribution of our paper, and we demonstrate this by building and evaluating a computational hybrid connectionist architecture SCREEN based on flat, robust, and learned processing.