We have experimented with the PARAMETRIC MICRO-HILLARY algorithm in the NxN puzzle domains using the above specifications. The resulting macro sets were tested on random 10 x 10 puzzles.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 15 shows the summary of 100 learning sessions. MICRO-HILLARY learned most of its macros by solving 3 x 3 and 4 x 4 puzzles. It typically learned one or two macros while solving 5 x 5 puzzles, and reached quiescence while solving 6 x 6 problems without learning any new macros. Note that on average at least 85% of the training problems and at least half of the learning time (operator applications) were used just for testing quiescence. Although PARAMETRIC MICRO-HILLARY solved 232 training problems on average compared with an average of 60 problems solved by MICRO-HILLARY in the 15-puzzle domain, the total learning CPU time is almost 3 times shorter than the time spent for learning the 15-puzzle. This is an indication that the method of solving problems in increasing level of difficulty indeed saves learning resources. PARAMETRIC MICRO-HILLARY was able to learn part of the macros while solving 3 x 3 puzzles, thus saving time by escaping local minima in a domain with a lower complexity.
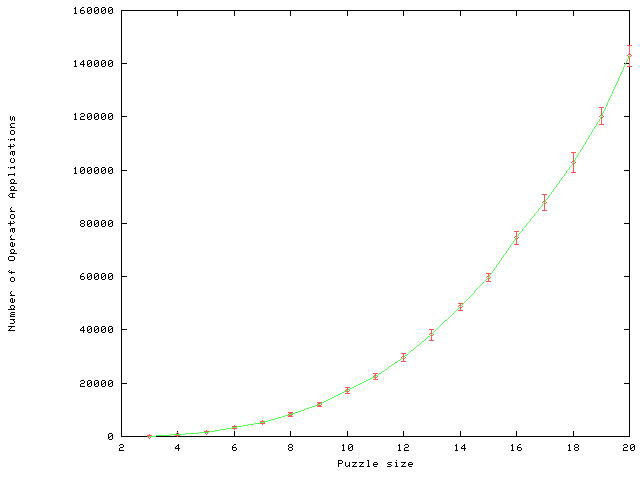
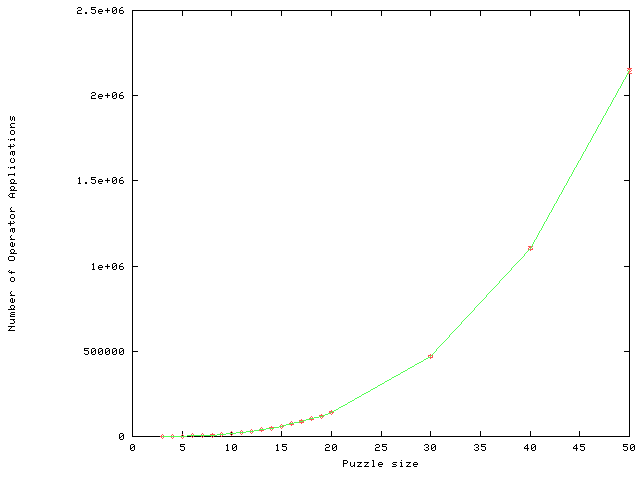
A second test was performed with one of the macro sets (we arbitrarily selected the one that was learned first). We generated sets of 10 random testing problems for various sizes up to 50 x 50 and solved these problems using the macro set. The random problems were generated, as in the previous section, by even random permutations.
 |
 |
Note that both the empirical results and the formal proof show that the maximal radius of any puzzle problem, regardless of the puzzle size, with respect to the RR heuristic, is bounded by 18. This bounded-radius property is a necessary condition for MICRO-HILLARY to scale up its acquired macros for domains with a larger parameter. It can be easily shown that the MD heuristic does not have such a property.
 |
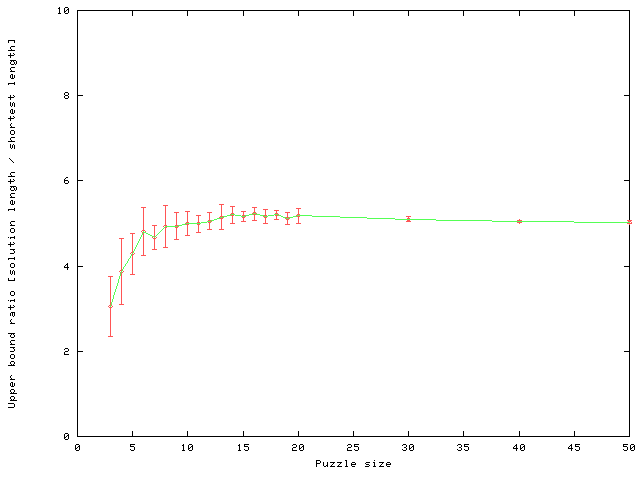 |
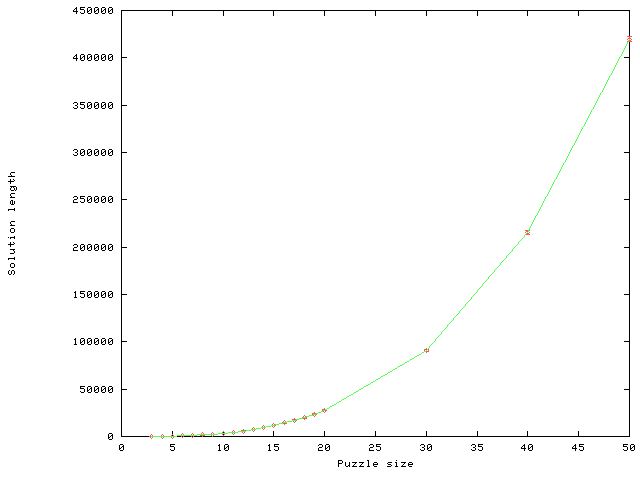
Figure 10(a) shows the mean solution length as a function of the puzzle size. Figure 10(b) shows the upper bound on the ratio of the solution length to the optimal solution length as a function of the puzzle size (the solution length divided by the sum-of-Manhattan-distances). It is interesting to note that the graph is flattened at a value of 5. Ratner and Warmuth [30,31] sketch a (quite complicated) hand-crafted approximation algorithm for the NxN puzzle. In their earlier paper they give a constant factor of 22 to the approximation. Looking at Figure 10, it is quite possible that MICRO-HILLARY could have found such an algorithm by itself. The constant factor of MICRO-HILLARY seems to be close to 5, but it is measured with respect to random problems, while Ratner and Warmuth's constant is a worst-case upper bound. In the appendix, we prove that the length of the solutions found by MICRO-HILLARY for NxN puzzle problems is O(N3) with a constant of 50 (which is substantially worse than Ratner and Warmuth's).