The focus model, or model of attentional state [10], is a model of which entities the dialog is most centrally about at each point in the dialog. It determines which previously mentioned entities are the candidate antecedents of anaphoric references. As such, it represents the role that the structure of the discourse plays in reference resolution.
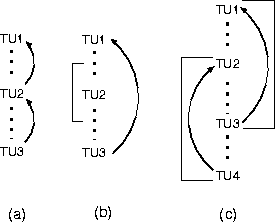
We consider three models of attentional state in this paper: (1) the linear-recency model (see, for example, the work by Hobbs [14] and Walker2 [39]), (2) Grosz and Sidner's [10] stack-based model, and (3) the graph structured stack model introduced by Rosé, Di Eugenio, Levin, and Van Ess-Dykema [31]. Ordered from (1) to (3), the models are successively more complex, accounting for increasingly more complex structures in the discourse.
In a linear-recency based model, entities mentioned in the discourse are stored on a focus list, ordered by recency. The corresponding structure in the dialog is shown in Figure 4a: a simple progression of references, uninterrupted by subdialogs.
| Dialog Date: Monday 10 May | |||
| 1 | S1 | Listen, daughter, I was thinking of inviting you to a demonstration on | |
| interior things, ornaments for decorating your house. | |||
| 2 | Uh, I would like to do it at two p.m. Wednesday, | ||
| 3 | But I don't know if you are free at that time or |
||
| TU1 | 4 | S2 | Uh, Wednesday, Mom, well |
| Resolved to Wednesday, May 12 | |||
| 5 | You know that, | ||
| TU2,1 | 6 | last week uh, I got a job and uh, a full-time job | |
| Unambiguous deictic; resolved to the week before the dialog date | |||
| TU2,2 | 7 | I go in from seven in the morning to five in the afternoon | |
| Habitual | |||
| 8 | S1 | Oh, maybe it would be better | |
| TU3 | 9 | S2 | Well, I have lunch from twelve to one |
| Utterance (4) is needed for the correct interpretation: | |||
| 12-1, Wednesday 12 May | |||
In this passage, utterances (6)-(7) are in a subdialog about S2's job. To interpret ``twelve to one'' in utterance (9) correctly, one must go back to utterance (4). Incorrect interpretations involving the temporal references in (6) and (7) are possible (using the co-reference relation with (6) and the modify relation with (7)), so those utterances must be skipped.
Rosé et al.'s graph structured stack is designed to handle the more complex structure depicted in Figure 4c. We will return to this structure later in Section 8.1, when the adequacy of our focus model is analyzed.
Once the candidate antecedents are determined, various
criteria can be used to choose among them.
Syntactic and semantic constraints
are common.