In ``A maximum entropy approach to natural language processing'' (Computational Linguistics 22:1, March 1996), the appendix describes an approach to computing the gain of a single feature f. This note elaborates on the equations presented there; in particular, we show how to derive equations (37) and (38).
Background
Recall the form of the model:
![]()
where
A typical measure of the quality of a model relative to some
empirical distribution ![]() is the log-likelihood:
is the log-likelihood:
![]()
Furthermore, we introduce the gain of a feature, which is the increase in
log-likelihood of the model ![]() relative to
relative to ![]() :
:
![]() arises as a natural and efficient approximation to
arises as a natural and efficient approximation to ![]() ;
see section 4.3 of the paper for details. Here
;
see section 4.3 of the paper for details. Here ![]() is the fraction of times
is the fraction of times ![]() in the empirical sample; in
other words, the ``empirical expected value'' of f.
in the empirical sample; in
other words, the ``empirical expected value'' of f.
Deriving ![]()
The efficient feature selection algorithm computes for each feature f the
optimal weight ![]() if f were to be adjoined to the set of active features
if f were to be adjoined to the set of active features
![]() , under the assumption that the other parameters remain fixed. Since the
optimal
, under the assumption that the other parameters remain fixed. Since the
optimal ![]() occurs at
occurs at ![]() , we can apply a numerical root-finding
technique (such as Newton's method) to
, we can apply a numerical root-finding
technique (such as Newton's method) to ![]() to locate the optimal
to locate the optimal
![]() . Under suitable conditions, a numerical root-finding technique is
guaranteed to move monotonically closer to the root with each iteration.
. Under suitable conditions, a numerical root-finding technique is
guaranteed to move monotonically closer to the root with each iteration.
Differentiating (3), we get
![]()
Introducing the abbreviation ![]() ,
we can rewrite this equation as
,
we can rewrite this equation as
For ![]() , we differentiate once more:
, we differentiate once more:

Before things get any hairier, we will write f for ![]() and introduce
and introduce ![]() . The notation (in the latter case) is meant to
indicate that
. The notation (in the latter case) is meant to
indicate that ![]() is a constant, not taking part in
summations. Carrying on, we have
is a constant, not taking part in
summations. Carrying on, we have
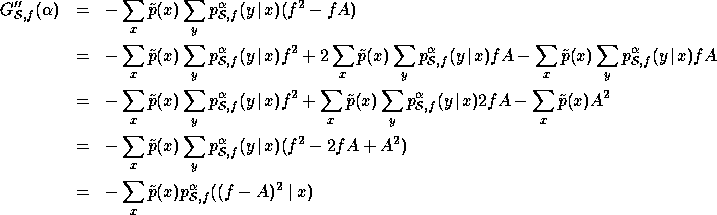
The last line matches equation (38) in the paper.
