Suppose that we are given n feature functions ![]() , which determine
statistics we feel are important in modeling the process. We would like our
model to accord with these statistics. That is, we would like
, which determine
statistics we feel are important in modeling the process. We would like our
model to accord with these statistics. That is, we would like ![]() to lie in
the subset
to lie in
the subset ![]() of
of ![]() defined by
defined by
Figure 1 provides a geometric interpretation of this
setup. Here ![]() is the space of all (unconditional) probability distributions
on 3 points, sometimes called a simplex. If we impose no constraints
(depicted in (a)), then all probability models are allowable. Imposing one
linear constraint
is the space of all (unconditional) probability distributions
on 3 points, sometimes called a simplex. If we impose no constraints
(depicted in (a)), then all probability models are allowable. Imposing one
linear constraint ![]() restricts us to those
restricts us to those ![]() which lie on the
region defined by
which lie on the
region defined by ![]() , as shown in (b). A second linear constraint could
determine
, as shown in (b). A second linear constraint could
determine ![]() exactly, if the two constraints are satisfiable; this is the
case in (c), where the intersection of
exactly, if the two constraints are satisfiable; this is the
case in (c), where the intersection of ![]() and
and ![]() is non-empty.
Alternatively, a second linear constraint could be inconsistent with the
first--for instance, the first might require that the probability of the first
point is
is non-empty.
Alternatively, a second linear constraint could be inconsistent with the
first--for instance, the first might require that the probability of the first
point is ![]() and the second that the probability of the third point is
and the second that the probability of the third point is
![]() --this is shown in (d). In the present setting, however, the linear
constraints are extracted from the training sample and cannot, by construction,
be inconsistent. Furthermore, the linear constraints in our applications will
not even come close to determining
--this is shown in (d). In the present setting, however, the linear
constraints are extracted from the training sample and cannot, by construction,
be inconsistent. Furthermore, the linear constraints in our applications will
not even come close to determining ![]() uniquely as they do in (c);
instead, the set
uniquely as they do in (c);
instead, the set ![]() of allowable
models will be infinite.
of allowable
models will be infinite.
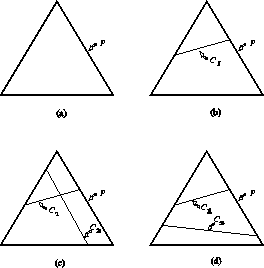
Figure 1: Four
different scenarios in constrained optimization. ![]() represents the space of
all probability distributions. In (a), no constraints are applied, and all
represents the space of
all probability distributions. In (a), no constraints are applied, and all
![]() are allowable. In (b), the constraint
are allowable. In (b), the constraint ![]() narrows the set of
allowable models to those which lie on the line defined by the linear
constraint. In (c), two consistent constraints
narrows the set of
allowable models to those which lie on the line defined by the linear
constraint. In (c), two consistent constraints ![]() and
and ![]() define a
single model
define a
single model ![]() . In (d), the two constraints are
inconsistent (i.e.
. In (d), the two constraints are
inconsistent (i.e. ![]() ); no
); no ![]() can satisfy them
both.
can satisfy them
both.
Among the models ![]() , the maximum entropy philosophy dictates that we
select the distribution which is most uniform. But now we face a question left
open earlier: what does ``uniform'' mean?
, the maximum entropy philosophy dictates that we
select the distribution which is most uniform. But now we face a question left
open earlier: what does ``uniform'' mean?
A mathematical measure of the uniformity of a conditional distribution ![]() is provided by the conditional entropy
is provided by the conditional entropy![]()
The entropy is bounded from below by zero, the entropy of a model with no
uncertainty at all, and from above by ![]() , the entropy of the uniform
distribution over all possible
, the entropy of the uniform
distribution over all possible ![]() values of y. With this definition in
hand, we are ready to present the principle of maximum entropy.
values of y. With this definition in
hand, we are ready to present the principle of maximum entropy.
To select a model from a setof allowed probability distributions, choose the model
with maximum entropy
:
It can be shown that ![]() is always well-defined; that is, there is
always a unique model
is always well-defined; that is, there is
always a unique model ![]() with maximum entropy in any constrained set
with maximum entropy in any constrained set
![]() .
.