Research Projects
My research is in machine learning and
statistics, with basic research on theory, methods, and
algorithms. Areas of focus include nonparametric
methods, sparsity, the analysis of high-dimensional data,
graphical models, information theory, and applications in
language processing, computer vision, and information retrieval.
Perspectives on several research topics in statistical machine learning
appeared in this Statistica
Sinica commentary.
This work has received support from NSF, ARDA, DARPA, AFOSR, and Google.
Some sample projects:
- Rodeo: Sparse, greedy, nonparametric regression
with Larry Wasserman
Ann. Statist., Vol. 36, No. 1 (2008), pp 28-63.
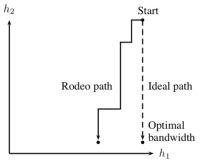 Estimating a high dimensional regression
function is notoriously difficult, due to the curse of
dimensionality—this curse can be characterized rigorously using
minimax theory. We developed on a new method for simultaneously
performing bandwidth selection and variable selection in
nonparametric regression that can beat the curse of dimensionality
when the underlying function is sparse. The method starts with a
local linear estimator with large bandwidths, and incrementally
decreases the bandwidth in directions where the gradient of the
estimator with respect to bandwidth is large. The method, called
"rodeo" (regularization of derivative expectation operator),
conducts a sequence of hypothesis tests, and is easy to implement.
Under certain
assumptions, the method achieves the optimal minimax rate of
convergence, up to logarithmic factors, as if the true relevant
variables were known in advance.
Estimating a high dimensional regression
function is notoriously difficult, due to the curse of
dimensionality—this curse can be characterized rigorously using
minimax theory. We developed on a new method for simultaneously
performing bandwidth selection and variable selection in
nonparametric regression that can beat the curse of dimensionality
when the underlying function is sparse. The method starts with a
local linear estimator with large bandwidths, and incrementally
decreases the bandwidth in directions where the gradient of the
estimator with respect to bandwidth is large. The method, called
"rodeo" (regularization of derivative expectation operator),
conducts a sequence of hypothesis tests, and is easy to implement.
Under certain
assumptions, the method achieves the optimal minimax rate of
convergence, up to logarithmic factors, as if the true relevant
variables were known in advance.
- Forest density estimation
with Haijie Gu, Anupam Gupta, Han Liu, Larry Wasserman and Min Xu
arXiv:1001.1557, 2010 (preliminary version in COLT 2010)
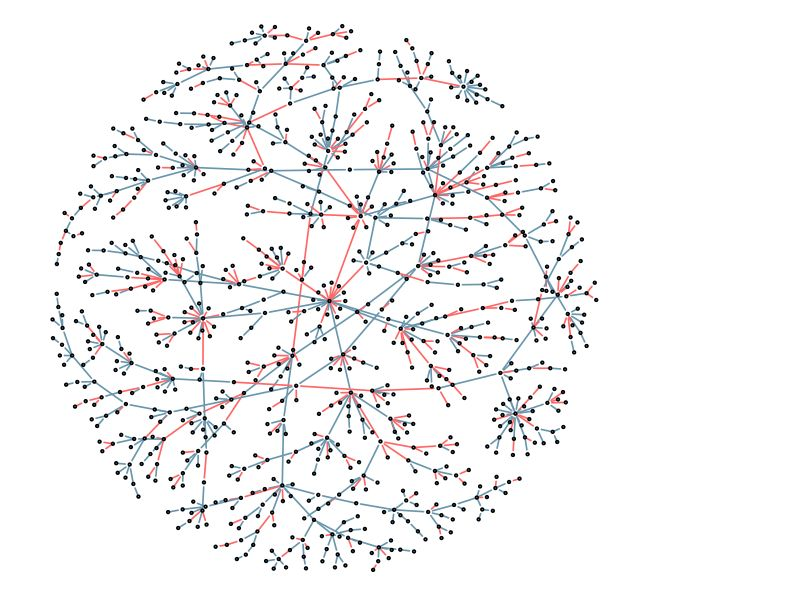 This project looks at both graph estimation
and density estimation in high dimensions. We use a family of
density estimators based on forest structured undirected
graphical models. We do not assume the
true distribution corresponds to a forest; rather, we form kernel
density estimates of the bivariate and univariate marginals, and
apply variants of Kruskal's algorithm to estimate the optimal
forest on held out data. We prove an oracle inequality on the
excess risk of the resulting estimator relative to the risk of
the best forest. For graph estimation, we consider the problem of
estimating forests with restricted tree sizes. We prove that
finding a maximum weight spanning forest with restricted tree
size is NP-hard, and develop an approximation algorithm for this
problem. Viewing the tree size as a complexity parameter, we then
select a forest using data splitting, and prove bounds on excess
risk and structure selection consistency of the procedure. To
estimate the densities on human gene expression data, we parallelize
the computations using GPU arrays.
This project looks at both graph estimation
and density estimation in high dimensions. We use a family of
density estimators based on forest structured undirected
graphical models. We do not assume the
true distribution corresponds to a forest; rather, we form kernel
density estimates of the bivariate and univariate marginals, and
apply variants of Kruskal's algorithm to estimate the optimal
forest on held out data. We prove an oracle inequality on the
excess risk of the resulting estimator relative to the risk of
the best forest. For graph estimation, we consider the problem of
estimating forests with restricted tree sizes. We prove that
finding a maximum weight spanning forest with restricted tree
size is NP-hard, and develop an approximation algorithm for this
problem. Viewing the tree size as a complexity parameter, we then
select a forest using data splitting, and prove bounds on excess
risk and structure selection consistency of the procedure. To
estimate the densities on human gene expression data, we parallelize
the computations using GPU arrays.
- A correlated topic model of Science
with Dave Blei
Ann. Appl. Statist., Vol. 1, No. 1, 17-35, 2007
Topic models, such as latent Dirichlet allocation (LDA), assume that the words of a document arise from a mixture of topics, each of which is a distribution over the vocabulary. A limitation of LDA is the inability to model topic correlation even though, for example, a document about sports is more likely to also be about health than international finance. We developed the correlated topic model (CTM), where the topic proportions exhibit correlation via the logistic normal distribution. The CTM provides a natural way of visualizing and exploring unstructured data sets. See www.cs.cmu.edu/~lemur/science for an example browser for the model fit on a collection of OCR articles from the journal Science. We also developed time series versions of these models to capture the time evolution of the underlying topics.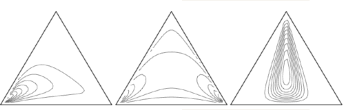
- The nonparanormal
with Han Liu and Larry Wasserman
Journal of Machine Learning Research, Volume 10, pp 2295-2328, 2009.
Most methods for estimating sparse undirected graphs for real-valued data in high dimensional problems rely heavily on the assumption of normality. We show how to use a semiparametric Gaussian copula, which we call the nonparanormal, for high dimensional inference. Just as additive models extend linear models by replacing linear functions with a set of one-dimensional smooth functions, the nonparanormal extends the normal by transforming the variables by smooth functions. We derive a method for estimating the nonparanormal, study the method's theoretical properties, and show that it works well in many examples.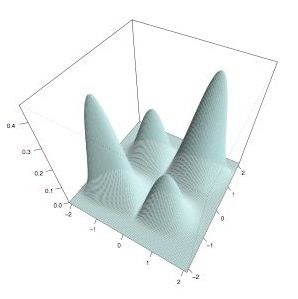
- Diffusion kernels on statistical manifolds
with Guy Lebanon
Journal of Machine Learning Research, Volume 6, pp 129-163, 2005.
We introduce a family of kernels for statistical learning that exploits the geometric structure of statistical models. The kernels are based on the heat equation on the Riemannian manifold defined by the Fisher information metric associated with a statistical family, and generalize the Gaussian kernel of Euclidean space. As an important special case, kernels based on the geometry of multinomial families are derived, leading to kernel-based learning algorithms that apply naturally to discrete data. Bounds on covering numbers and Rademacher averages for the kernels are proved using bounds on the eigenvalues of the Laplacian on Riemannian manifolds.