In the homogeneous non-communicating version of the pursuit domain, rather than having one agent controlling all four predators, there is one identical agent per predator. Although the agents have identical capabilities and decision procedures, they may have limited information about each other's internal state and sensory inputs. Thus they may not be able to predict each other's actions. The pursuit domain with homogeneous agents is illustrated in Figure 6.
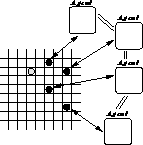
Figure 6: The pursuit domain with homogeneous agents. There is one
identical agent per predator. Agents may have (the same amount of)
limited information about other agents' internal states.
Within this framework, Stephens and Merx propose a simple heuristic behavior for each agent that is based on local information [81]. They define capture positions as the four positions adjacent to the prey. They then propose a ``local'' strategy whereby each predator agent determines the capture position to which it is closest and moves towards that position. The predators cannot see each other, so they cannot aim at different capture positions. Of course a problem with this heuristic is that two or more predators may move towards the same capture position, blocking each other as they approach. This strategy is not very successful, but it serves as a basis for comparison with two other control strategies--``distributed'' and ``central''--that are discussed in Section 6.
Since the predators are identical, they can easily predict each other's actions given knowledge of each other's sensory input. Such prediction can be useful when the agents move simultaneously and would like to base their actions on where the other predators will be at the next time step. Vidal and Durfee analyze such a situation using the Recursive Modeling Method (RMM) [90]. RMM is discussed in more detail below, but the basic idea is that predator A bases its move on the predicted move of predator B and vice versa. Since the resulting reasoning can recurse indefinitely, it is important for the agents to bound the amount of reasoning they use either in terms of time or in terms of levels of recursion. Vidal and Durfee's Limited Rationality RMM algorithm is designed to take such considerations into account [90].
Levy and Rosenschein use a game theoretical approach to the pursuit domain [48]. They use a payoff function that allows selfish agents to cooperate. A requirement for their model is that each predator has full information about the location of other predators. Their game model mixes game-theoretical cooperative and non-cooperative games.
Korf also takes the approach that each agent should try to greedily maximize its own local utility [46]. He introduces a policy for each predator based on an attractive force to the prey and a repulsive force from the other predators. Thus the predators tend to approach the prey from different sides. This policy is very successful, especially in the diagonal (agents can move diagonally as well as orthogonally) and hexagonal (hexagonal grid) games. Korf draws the conclusion that explicit cooperation is rarely necessary or useful, at least in the pursuit domain and perhaps more broadly:
We view this work as additional support for the theory that much coordination and cooperation in both natural and man-made systems can be viewed as an emergent property of the interaction of greedy agents maximizing their particular utility functions in the presence of environmental constraints.
Richard Korf [46]
However, whether or not altruism occurs in nature, there is certainly some use for benevolent agents in MAS, as shown below. More pressingly, if Korf's claim that the pursuit domain is easily solved with local greedy heuristics were true, there would be no point in studying the pursuit domain any further. Fortunately, Haynes and Sen show that Korf's heuristics do not work for certain instantiations of the domain [36] (see Section 5).