Empirical testing has demonstrated that TPOT-RL can effectively learn multi-agent control policies with very few training instances in a complex, dynamic domain. Figure 2(a) plots cumulative goals scored by a learning soccer team playing against an otherwise equally-skilled team that passes to random destinations over the course of a single long run equivalent in time to 160 10-minute games. In this experiment, and in all the remaining ones, the learning agents start out acting randomly and with empty Q-tables. Over the course of the games, the probability of acting randomly as opposed to taking the action with the maximum Q-value decreases linearly over periods of 40 games from 1 to .5 in game 40, to .1 in game 80, to point .01 in game 120 and thereafter. As apparent from the graph, the team using TPOT-RL learns to vastly outperform the randomly passing team. During this experiment, |U| = 1, thus rendering the function e irrelevant: the only relevant state feature is the player's position on the field.
A key characteristic of TPOT-RL is the ability to learn with minimal training examples. During the run graphed in Figure 2(a), the 11 players got an average of 1490 action-reinforcement pairs over 160 games. Thus, players only get reinforcement an average of 9.3 times each game, or less than once every minute. Since each player has 8 actions from which to choose, each is only tried an average of 186.3 times over 160 games, or just over once every game. Under these training circumstances, very efficient learning is clearly needed.
TPOT-RL is effective not only against random teams, but also against goal-directed, hand-coded teams. For testing purposes, we constructed an opponent team which plays with all of its players on the same side of the field, leaving the other side open as illustrated by the white team in Figure 1. The agents use a hand-coded policy which directs them to pass the ball up the side of the field to the forwards who then shoot on goal. The team periodically switches from one side of the field to the other. We call this team the ``switching team.''
Were the opponent team to always stay on the same side of the field, the learning team could always advance the ball up the other side of the field without any regard for current player positions. Thus, TPOT-RL could be run with |U| = 1, which renders e inconsequential. Indeed, we verified empirically that TPOT-RL is able to learn an effective policy against such an opponent using |U|=1.
Against the switching team, a player's best action depends on the current state. Thus a feature that discriminates among possible actions dynamically can help TPOT-RL. Figure 2(b) compares TPOT-RL with different functions e and different sets W when learning against the switching team.
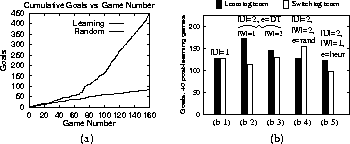
Figure 2:
(a) Cumulative goals scored by a learning team playing against a
randomly passing team. The independent variable is the number of
10-minute game intervals that have elapsed. (b) The results
after training of 5 different TPOT-RL runs against the switching
team.
With |U|=1 (Figure 2(b.1)), the learning team is unable to capture different opponent states since each player has only one Q-value associated with each possible action, losing 139-127 (cumulative score over 40 games after 160 games of training). Recall that if |U|=1 the function e cannot discriminate between different classes of states: we end up with a poor state generalization.
In contrast, with the previously trained DT classifying passes as likely successes or failures (e = DT) and TPOT-RL filtering out the failures, the learning team wins 172-113 (Figure 2(b.2)). Therefore the learned pass-evaluation feature is able to usefully distinguish among possible actions and help TPOT-RL to learn a successful action policy. The DT also helps learning when W=U (Figure 2(b.3)), but when |W|=1 performance is better.
Figure 2(b.4) demonstrates the value of using an informative action-dependent feature function e. When a random function e = rand is used, TPOT-RL performs noticeably worse than when using the DT. For the random e we show |W| = 2 because it only makes sense to filter out actions when e contains useful information. Indeed, when e = rand and |W|=1, the learning team performs even worse than when |W| = 2 (it loses 167-60). The DT even helps TPOT-RL more than a hand-coded heuristic pass-evaluation function (e = heur) based on one that we successfully used on our real robot team [18] (Figure 2(b.5)).
Final score is the ultimate performance measure. However, we examined learning more closely in the best case experiment (e = DT, |W| = 1 -- Figure 2(b.2)). Recall that the learned feature provides no information about which actions are strategically good. TPOT-RL must learn that on its own. To test that it is indeed learning to advance the ball towards the opponent's goal (other than by final score), we calculated the number of times each action was predicted to succeed by e and the number of times it was actually selected by TPOT-RL after training. Throughout the entire team, the 3 of 8 actions towards the opponent's goal were selected 6437/9967 = 64.6% of the times that they were available after filtering. Thus TPOT-RL learns that it is, in general, better to advance the ball towards the opponent's goal.
To test that the filter was eliminating action choices based on likelihood of failure we found that 39.6% of action options were filtered out when e = DT and |W| = 1. Out of 10,400 actions, it was never the case that all 8 actions were filtered out.