TL;DR
- We have launched a new on-line research resource called the Carnegie Mellon Database Application Catalog that contains a collection of ready-to-run applications for benchmarking, experimentation, and analysis.
My last couple of blog posts have been all retrospectives on things that have passed. That is, I have been looking back on previous research and work. While it's nice to take stock on things that one has accomplished, it's more fun to discuss the new stuff coming out now. The always swarmy Leon Wrinkles once told me that a goat never defecates in the same place twice. I usually can't understand his ribald metaphors, but I think I know what he means for this. So this summer all of my posts will be about the new projects that we have been working on in the last three years at CMU.
With that, I am pleased to announce the release of the Carnegie Mellon Database Application Catalog (CMDBAC). The CMDBAC is a collection of open-source database applications that you can automatically deploy and execute locally for benchmarking and experimentation.
Background
One of the hardest parts about database systems research in academia is that you do not have easy access to workloads and data sets. These are important because it allows us to guide our research to work on problems that people care about. Students often ask me how often certain scenarios or corner cases appear in real-world applications[1]. Sometimes I can answer based on my experiences or from conversations that I had with my contacts in industry, but I have no way of quantitatively justifying my answers.
The current standard for database workloads are the TPC benchmarks. I contend that these are not enough. We already created a benchmark suite that includes these TPC workloads along with additional ones (e.g., clones of Twitter, Wikipedia, Epinions), but I feel that these do not capture the full complexity and variety of enterprise applications. When I was a naïve grad student I tried to get data sets from companies but I was always stymied by lawyers and NDAs. The only time that I was able to get real workload samples was when early MongoDB customers sent us anonymized mongosniff traces. This was back in 2011 when we were working on an automated database design tool for document DBMSs[2].
Others have been more successful at establishing companies that allow them to work with real customers. Stonebraker is obviously the king of this in the database world. This is (probably) not something that I am keen on pursuing at this point in my career, especially before I am up for tenure. Dan Abadi has publicly discussed his thoughts on this both before and after he got tenure at Yale.
Thus, we need to look at alternative ways to get real (or as real as possible) workloads that does not require lawyers, CMU's IRB, or customers.
CMDBAC
The CMDBAC is an on-line repository that allows you to search for applications that have workload properties that are relevant to your research. For example, you can search for applications that have a lot of secondary indexes or have read-modify-write workload patterns. The CMDBAC has already figured out how safely deploy each application, including their library dependencies and runtime environment, and then how to run them. We provide a Python-based tool that allows you to download an application and run it in your local environment with zero configuration. You just tell it what DBMS to point it at and it will automatically populate the database (with synthetic data) and execute actions in the application (again, with synthetic data and workload distributions). You can then collect query traces for further analysis and testing.
The CMDBAC currently contains over 1000 applications of varying complexity. We target Web applications based on popular programming frameworks because (1) they are easier to find and (2) we can automate the deployment process. We support applications that use the Django, Ruby on Rails, Drupal, Node.js, and Grails frameworks.
 CMDBAC Main Page |
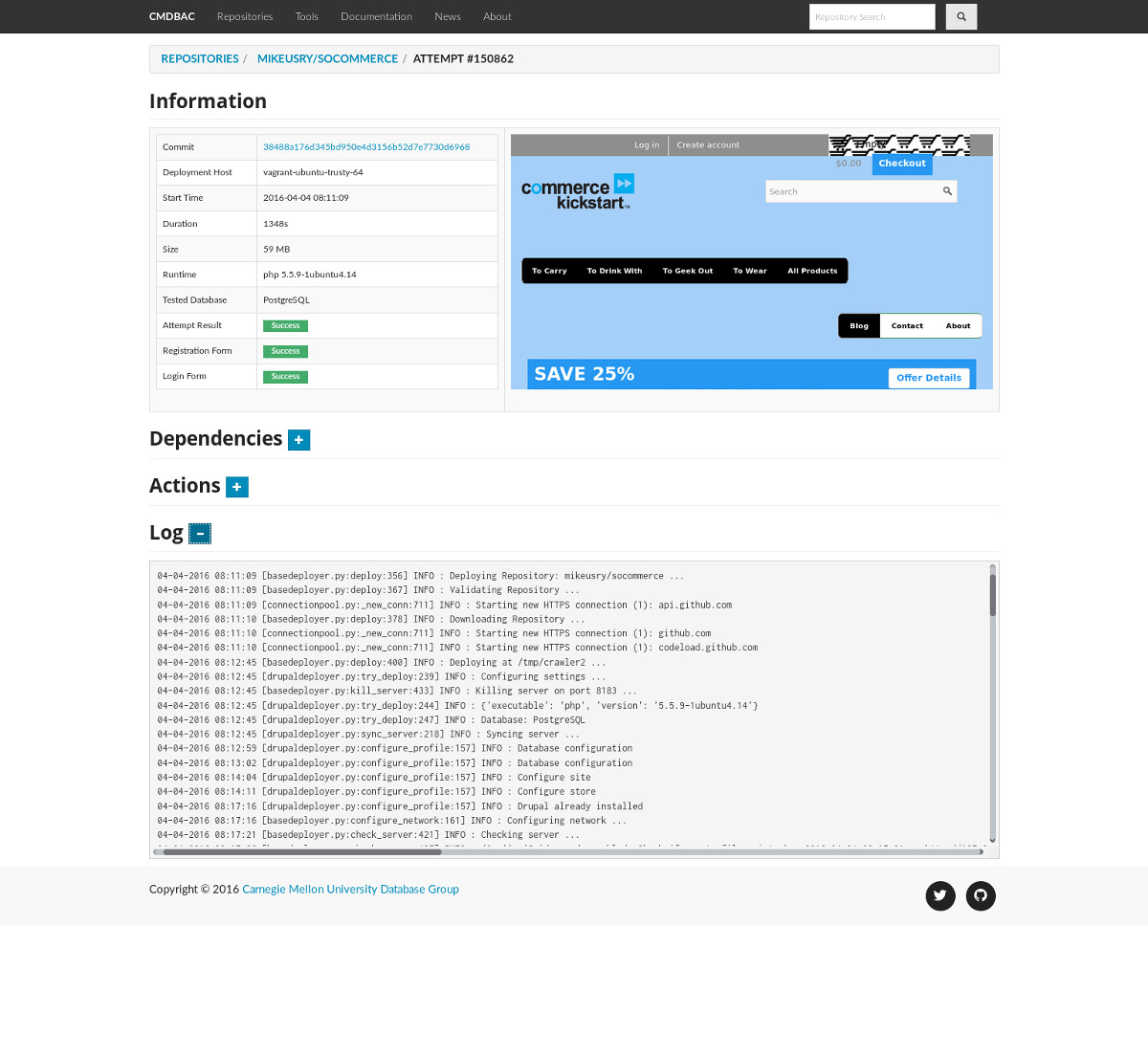 Application Deployment Attempt Page |
The CMDBAC framework consists of three parts. The first is a crawler that searches for applications on public source code hosting websites. These applications are then provided to a deployer that attempts to installs and configure them inside of a sandbox. The deployer will try to install an application multiple times until it learns the proper configuration. Once an application is successful deployed, we then inject a driver into the sandbox that automatically figures out how to fill in forms for the application, thereby causing it to interact with its underlying database. The driver captures the queries that the application executes and stores it in CMDBAC's database for further analysis.
I will now describe some of the interesting technical details and challenges that we had to overcome. We are working on a full paper later this summer that provides more information as well as our analysis of the applications themselves.
Step #1: Crawler
The crawler searches the hosting website for applications based on common filenames and directory structures. For example, Django applications always contain a file called manage.py in its root directory. This file gets created when the programmer sets up a new Django project for the first time. Thus, if we see a repository with this file then it is likely to be a Django application. All of the other frameworks have similar files.
The CMDBAC currently only supports crawling GitHub, since they are the largest hosting company[3]. The crawler uses BeautifulSoup to scrap search results by looking for the indicative file names and a file size. The latter seeds our search request and allows us to get more results than we would get if we just searched for the filename by itself. We then use the official GitHub API to collect additional meta-data about each application (e.g., timestamps, number of commits). We use this to estimate the popularity of a repository and allows us to focus our efforts on the applications that we expect to be more complex (and thus have more interesting workloads).
The crawler currently does not perform any filtering based on whether a repository was forked from another one. From our cursory analysis we have also found that many repositories are straight copies of others but without any provenance lineage information.
Step #2: Deployer
In the next phase, the deployer then downloads any found application and attempts to run them inside of a Vagrant sandbox. We deploy the applications using the Apache webserver and MySQL.
We can automate this entire process because the steps to deploy each application for a given framework will be (almost) the same. There are some cases whether the application requires additional manual steps. For example, we found some applications require executing an additional shell script or providing an authentication key from a third-party cloud provider (e.g., Google's reCAPTCHA). The CMDBAC will mark these applications are non-deployable.
Many applications also require third-party libraries to be installed in the sandbox that are not included in the repository. Some frameworks provide some hints or guidelines on what dependencies are required. Using Django as an example again, some repositories include a requirements.txt that specifies what packages they need. But not all applications include this file and they are often incomplete. Thus, the deployer will repeatedly try to run an application and then captures any errors that reference a missing module. The CMDBAC includes a database that we generated from scraping the different programming language library websites (e.g., pip's package index). This allows the deployer to easily identify what package to install for a given error message. This works for nearly all of the "missing module" errors that we find.
Another challenge that we had to solve is finding the proper framework and language runtime versions. This is again not something that is easily discernible from the repository. The deployer tries to install an application multiple times until it finds the correct combination. We mark that a deployment is successful if we do not incur any errors either during start-up or when we can access the application's main page the first time. If the deployer fails to find a configuration that does not produce any errors, then it marks the application as non-deployable. We found that getting the right version of Ruby for the Ruby on Rails applications was the most fastidious of all the frameworks.
There are obviously many security issues with downloading and running arbitrary code on a machine inside of the university's network. To avoid any problems, we lock down the sandbox to prevent outside network connections or access to the host machine's filesystem. This is also why we use the CMDBAC's built-in dependency database; it allows us to install packages off-line to avoid certain attacks.
Step #3: Driver
At this point we now have an application that can be successfully deployed inside of a VM. We now want to execute "actions" in the application that cause it to interact with the database so that we can capture the queries. We define an action as either a GET or POST operation on the web server.
CMDBAC's driver component has two execution modes. The first is to pre-populate the database with initial data. This is necessary because not all applications include initialization files (e.g., Django's fixtures). We use the different frameworks' built-in administration forms to do this rather than trying to generate random data in the database tables directly. This is because the application may include additional logic that is not captured in the database DDL. An example of this could be application-level code that updates the database whenever the framework's ORM save method is triggered.
The driver's second mode is where it interacts with the user-facing interface of the application. These are the pages and forms that a regular user would encounter when visiting the website through their browser. The main challenge with this mode is that some applications only expose functionalities to logged in users. That means we have to figure out how to automatically register an account. We again could not rely on directly adding a user account into the database with raw SQL because not all applications use the same user management code. But now the two problems that we faced with automatic registration are verification emails and CAPTCHAs.
Dealing with the verification emails is easy. We configure the sandbox to redirect all outbound SMTP messages to a file and then extract any URL that gets appended to that file. The driver then just visits that URL. This solved any email-based verification requirement almost every single time.
Recall from above that CMDBAC's deployer will not configure applications that required external services to operate. This means that we cannot run applications that are protected by reCAPTCHA or OAuth. Therefore, the only CAPTCHAs that we encounter are more simplistic variants. The first were simple math problems that are easily bypassed with Python's eval function.

The next kind of protection mechanism used CSS to hide certain form elements from humans (e.g., display:none). In the example below, we show two registration forms for the same application. The first one is just the raw HTML that is given to the user. As you can see, it includes fields for the user's "Address" and "Phone" information. The second screenshot is the same form but with the CSS stylesheet is applied. Now we see that the "Address" and "Phone" fields are removed. Thus, if our deployer attempts to register and populates data in these two fields that should be hidden, then the application knows that the request is not from a human and rejects the registration.
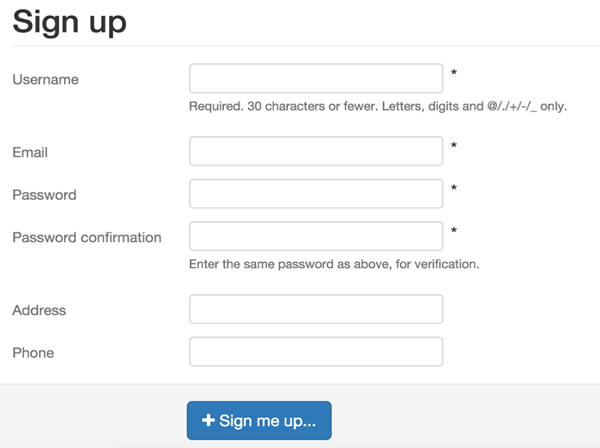 Raw HTML Form |
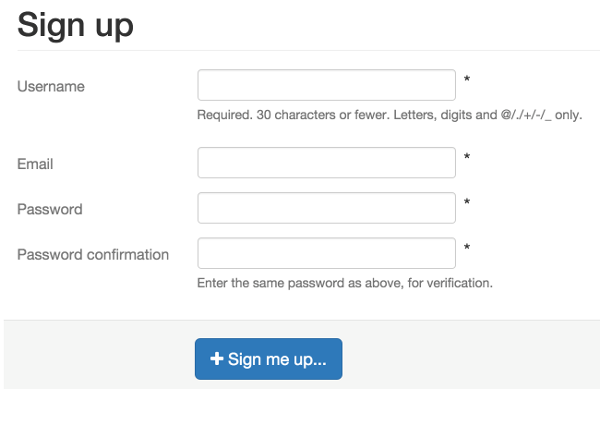 Form with CSS enabled |
To get around this issue, we use Python's mechanize library to create a virtual browser that executes CSS and JavaScript for each page. The driver then checks before submitting the form whether a field should be hidden.
Regardless of whether the driver is able to register an account and log in, it then crawls the application to find pages and forms. For each form that the driver finds in the application, it populates that form's fields with random information using heuristics based on its type. It then submits this form and capture a query trace that the application executes in order to process the form request. We enable query logging in the sandbox's DBMS (e.g., MySQL's general log). We also use uniquely identifiable values for the forms that allows us to map a form field to an database attribute accessed in the queries. This is sort of a variant of taint checking.
All of this information generated from a deployment attempt is recorded in the CMDBAC's database and presented on the website.
Execution Tool
The last piece of CMDBAC is the command-line tool that allows you to download any application (based on an attempt number) and deploy it locally. This script will create the same Vagrant sandbox that we used in our analysis that is configured to block all outbound network connections. You can then let the system run for as long as you want to capture enough query traces.
Note that you should not run an application from the catalog outside of the sandbox. We have not vetted them for safety. We are only providing this tool to allow you to run them more easily.
Future Plans
There are a couple of improvements that we want to pursue in expanding the scope of CMDBAC's applications. Foremost is that we are interested in adding more complex applications to the catalog. My intuition is that these applications are going to be written in a more "enterprise" language, like Java or C#. That means we want to be able to support applications that use more heavy-weight frameworks like Tomcat or WildFly (previously known as JBoss). It is not clear, however, how many of these applications will be open-source and hosted on a website like GitHub.
We think that there are also some additional tricks that we can use to increase the number of applications that we can successfully deploy.
We may also need to employ some data cleaning to our query traces. Some applications, especially Ruby on Rails, periodically execute queries that poll the database for new entries or to check whether a connection is still alive (e.g., SELECT 1). These queries are incorrectly included into the queries that we capture for an action.
The original plan was to use CMDBAC to study how applications use transactions and empirically understand how their correctness is affected by isolation levels[4]. Peter Bailis (aka the "human laxative of databases") already beat me to part of this with his Feral Concurrency Control paper in SIGMOD'15. I'm not knocking him. It is a solid paper that I wish I wrote. We found the same thing that Peter showed in his paper: applications that use these frameworks almost never use transactions. That means I need to reconsider how I plan on pursuing this research topic.
Conclusion
The CMDBAC currently contains over 1000 applications that we are able to run to some degree. Not all of these applications are interesting. Many of them are just the framework scaffolding. Others are the same project that people have implemented from following an on-line tutorial. A good way to find the interesting applications is to sort them by the number of actions and/or queries, or to use additional filters to find ones with a large number of tables.
All of the source code for CMDBAC is under the Apache Software License and is available on GitHub.
The CMDBAC was developed by Zeyuan Shang (Tsinghua), Fangyu Gao (CMU), and Dana Van Aken (CMU). This research was funded (in part) by the U.S. National Science Foundation (III-1423210).
Footnotes
- The one question that we have now is how often blind writes occur.
- We had to abandon this project because MongoDB did not have a cost-based query optimizer. Thus, it became too difficult to determine whether one design for MongoDB was better than another. See this seminal paper from MSR for why this matters.
- We plan to support BitBucket and Gitlab in the future. Where's your god now?
- This is actually part 3 in my open-problems in transaction processing series that I still need to write about. See previous posts for part 1 and part 2.