 |
Ion Stoica, Mihai Budiu -- istoica+@cs.cmu.edu, mihaib+@cs.cmu.edu
http://www.cs.cmu.edu/~istoica,
http://www.cs.cmu.edu/~mihaib
18 aprilie 1999
În acest articol ilustrăm una dintre direcţiile cercetării contemporane în domeniul Internetului: căutarea de algoritmi practici pentru a rezolva felurite probleme; problema pe care o ilustrăm este cea a alocării echitabile a traficului pe legăturile dintre calculatoare, în aşa fel încît toţi participanţii la trafic să primească aceeaşi cantitate. Deşi infrastructura curentă a Internetului nu permite acest lucru, implementarea acestui gen de algoritmi va fi necesară pentru a transforma Internetul într-o reţea care poate garanta calitatea serviciilor pe care le oferă.
Internetul este o reţea compusă din agregarea unui mare număr de reţele diferite într-o construcţie unică. Dacă două organizaţii au reţelele lor proprii, folosind tehnologii eventual diferite, aceste două reţele pot fi conectate între ele cu ajutorul unui calculator special, care este cuplat la ambele reţele. Rolul acestui calculator este de a prelua dintr-o reţea datele care sunt destinate cuiva din cealaltă reţea şi de a le retransmite dincolo. Această funcţiune se numeşte rutare, iar calculatorul însuşi se numeşte ruter.
Un ruter are deci două funcţiuni:
Într-un articol anterior din PC Report, Mihai a prezentat (a), rutarea în Internet1. Subiectul acelui articol era modul în care ruterele învaţă încotro trebuie trimis fiecare pachet primit, şi modul în care ruterele schimbă între ele informaţii despre structura reţelei.
În textul de faţă vom complementa informaţiile oferite cu acea ocazie, discutînd despre (b), modul în care ruterele transmit pachete.
Un ruter este legat la fiecare reţea pe care o deserveşte printr-o interfaţă. Un ruter va avea deci cel puţin două interfeţe. Cînd un pachet apare prin una din interfeţe, ruterul pune acel pachet într-o memorie internă. După aceea ruterul prelucrează pachetul şi decide în ce direcţie trebuie să-l trimită. Această informaţie este obţinută din adresa destinaţie, care se află în interiorul pachetului, şi din tabela de rutare, care conţine informaţii despre forma reţelei, şi pe care ruterul a construit-o conversînd cu vecinii săi. După ce decide încotro trebuie trimis pachetul, ruterul îl trimite pe interfaţa care este cea mai potrivită pentru destinaţie.
Figura 1 ilustrează arhitectura internă a unui ruter.
|
Aparent nimic nu este mai simplu: iei pachetul, cauţi destinaţia în tabelă, şi îl trimiţi mai departe. O astfel de operaţie se numeşte stochează şi transmite (store and forward), din motive evidente. Ce mai e de discutat aici?
Dacă veţi încerca însă să construiţi un ruter, veţi vedea că există o sumedenie de întrebări la care răspunsul nu este de loc evident. Iată unele din dificultăţile care se pot ivi:
Din cauza aceasta, ruterele conţin memorii, numite buffere, în care stochează pachetele pe care nu le pot prelucra. Pachetele se aşează în cozi, de unde sunt extrase unul cîte unul. Este clar însă că, oricît de multe buffere am avea, rafale mari de pachete pentru aceeaşi destinaţie pot umple cozile, cauzînd din nou pierderea pachetelor.
Una peste alta, un ruter trebuie să ia următoarele decizii:
Modul în care ia aceste decizii are consecinţe foarte importante pentru comportarea reţelei. În acest articol vom vedea cîteva posibilităţi şi vom explora consecinţele lor, care sunt adesea foarte diferite.
Trebuie spus însă că majoritatea covîrşitoare a disciplinelor studiate nu sunt implementate în sisteme reale, fiind deocamdată doar un subiect de cercetare. Practic toate ruterele operaţionale astăzi în lume folosesc o disciplină foarte simplă: au o singură coadă pentru fiecare interfaţă, în care pun toate pachetele. Cînd coada este plină, noile pachete venite sunt pierdute. Această disciplină se numeşte FIFO: First In First Out, primul venit, primul plecat.
Din nefericire, deşi extrem de simplu de implementat, FIFO are nişte proprietăţi indezirabile, despre care vom discuta puţin mai jos, în secţiunea despre Fair Queuing, unde ilustrăm şi o alternativă. FIFO este inadecvată din multe puncte de vedere, aşa că multe eforturi în cercetare sunt acum îndreptate spre studiul altor discipline.
Însă, înainte de a vedea exemple de alte discipline, vom pune sub reflector o proprietate extrem de importantă a reţelei, care este influenţată de modul în care ruterele şi punctele terminale operează. Este vorba despre congestie.
Atunci cînd un segment al reţelei este înecat cu pachete pe care nu le poate transmite se produce un fenomen de congestie. Congestia este extrem de periculoasă, pentru că dacă nu este tratată corect poate periclita funcţionarea întregii reţele pentru o perioadă nedeterminată.
Scenariul cel mai sumbru arată astfel: o anumită legătură primeşte mai multe pachete decît capacitatea ei de transport. Ca atare, după ce cozile se umplu, inevitabil ruterul care deserveşte acea legătură începe să piardă pachete. După o vreme sursele care au trimis acele pachete încep să dea semne de îngrijorare, pentru că nu primesc confirmarea de primire; ca atare încep să retransmită pachetele pierdute. Acestea vor cauza creşterea mai mare a congestiei, pentru că folosesc acelaşi traseu. Cu cît reţeaua este mai blocată, cu atît mai multe pachete duplicate vor apărea (din cauza retransmisiilor), şi cu atît mai blocată va fi. Din această situaţie nu există ieşire, dacă nu se intervine imediat; reţeaua devine rapid nefuncţională.
Observaţi că acest lucru se poate petrece chiar dacă fiecare calculator terminal nu emite prea multe date; efectul se produce datorită agregării traficului de la mai multe conexiuni pe o legătură fizică comună. De exemplu, în figura 1, traficul între calculatoare din stînga şi oricare calculator din dreapta trebuie să treacă pe linia dintre cele două rutere.
În teoria reţelelor de transmisiuni de date se face distincţie între două clase de algoritmi:
Între aceste două clase există o suprapunere, pentru că o reducere a fluxului în mod implicit va reduce şi congestia. De fapt secţiunea următoare discută singura soluţie actualmente implementată pe scară largă în Internet, folosită de protocolul TCP, care administrează fluxuri între două calculatoare.
Soluţia folosită la ora actuală de majoritatea implementărilor existente ale protocolului TCP a fost propusă de van Jacobson în 1988. Pentru a o înţelege ar trebui să studiem un tip special de protocol, numit protocolul cu fereastră glisantă (sliding window). Subiectul este deosebit de interesant, dar prea generos pentru acest articol, care are are un alt subiect. Sperăm să putem trata acest subiect într-un alt articol; pentru cititorul impacient trimitem la cartea lui Tanenbaum publicată de editura Agora, ``Reţele de Calculatoare''.
Din protocolul cu fereastră glisantă vom reţine numai însuşirile care ne interesează.
TCP este un protocol care garantează trimiterea cu succes a tuturor pachetelor. Pentru asta, toate pachetele care nu au fost confirmate la primire de către capătul celălalt sunt păstrate de emiţător, chiar şi după ce au fost deja transmise. Pentru că între trimiterea unui pachet şi recepţia confirmării se poate scurge mult timp, emiţătorul este gata să emită mai multe pachete la rînd, chiar dacă nu a primit confirmări pentru nici unul. Numărul de pachete care se pot afla în tranzit fără confirmare se numeşte fereastră (window).
Fereastra glisantă este folosită de TCP cu succes şi pentru controlul fluxului. Iată cum:
Soluţia aceasta este deosebit de elegantă. Principala ei calitate este că nu implică de loc reţeaua: numai nodurile terminale rulează acest algoritm, fără nici un fel de informaţii de la rutere. În plus, această soluţie funcţionează indiferent de politica după care ruterele din reţea aruncă pachete.
Controlul congestiei prin variaţia ferestrei are mai multe dezavantaje, dar noi aici ne vom opri asupra unuia singur dintre ele. Să ne imaginăm că avem cinci fluxuri printr-o legătură congestionată. Să ne mai imaginăm că 4 dintre ele sunt implementări ``normale'' ale TCP, dar că unul dintre ele este o implementare foarte agresivă, care în loc să-şi reducă traficul, îl păstrează neschimbat.
Ce se va întîmpla este uşor de imaginat: cele patru fluxuri civilizate vor reduce traficul aşa cum trebuie, iar cel agresiv va folosi toată capacitatea posibilă a reţelei. În măsura în care acest flux de unul singur nu congestionează reţeaua, va funcţiona bine-mersi, furînd din porţia tuturor celorlalţi.
Dacă toate fluxurile ar fi lacome reţeaua s-ar congestiona iremediabil, şi nimeni n-ar primi nimic. Deci schema aceasta funcţionează numai dacă aproape toată lumea este rezonabilă.
Partea neplăcută este că această situaţie este deja întîlnită, într-o formă sau alta, în Internet:
Aplicaţiile de genul celor de mai sus folosesc protocolul UDP pentru transmisiune, care nu este fiabil, şi nu face nici un fel de control al fluxului sau congestiei.
De altfel puteţi face chiar dumneavoastră un experiment simplu dacă aveţi acces la două calculatoare legate în reţea, oarecare cunoştinţe de programare de reţea şi o oră liberă:
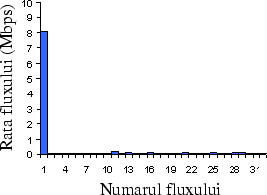 |
Veţi observa că legătura UDP obligă toate legăturile TCP să-şi reducă traficul, folosind de una singură toată capacitatea reţelei. Suma dintre UDP şi toate TCP-urile va fi constantă, TCP-urile vor fi aproximativ egale între ele, dar la o valoare mult mai scăzută decît legătura UDP.
De fapt, dacă ruterele tratează pachetele în ordinea sosirii (FIFO), şi le aruncă pe cele de la coadă, nici nu putem face mare lucru. O disciplină simplă ca FIFO nu poate asigura o distribuţie echitabilă a capacităţii în caz de congestie.
O soluţie, propusă în literatură, pentru aceasta problema este utilizarea de discipline mai ``inteligente'' în rutere. O astfel de disciplină este Fair Queueing (``cozi echitabile'', FQ). În continuare vom descrie FQ şi vom arăta că, spre deosebire de FIFO, această disciplină asigură o distribuţie echitabilă a capacităţii, independent de algoritmii de adaptare folosiţi de surse.
FQ este definit în contextul unui sistem ideal, în care traficul este transmis la nivel de biţi, şi nu de pachete. FQ se aplică la fiecare coadă de ieşire separat: fiecare interfaţă a ruterului va calcula pentru propriul ei canal. Într-un astfel de sistem, FQ se reduce la tratarea fluxurilor în mod circular (round-robin: în ordine fluxul 1, 2, 3, ..., n, 1, 2, 3, etc.). Mai precis, în cadrul fiecărei runde, FQ transmite un bit de la fiecare flux care este activ.
Spre deosebire de FIFO, FQ asigură alocarea echitabilă a capacităţii. În particular, capacitatea alocată unui flux nu depinde de rata fluxului. De exemplu, dacă avem o conexiune de 1 Mbps şi două fluxuri, unul cu rata de 0.5 Mbps şi altul de 2 Mbps, atunci fiecare flux va primi 0.5 Mbps. Aceasta se întîmplă deoarece atîta timp cît cele două fluxuri sunt active, fiecare va avea exact un bit transmis în cadrul fiecărei runde.
Evident, într-un ruter real în care transmisia se face la nivel de pachete şi nu de biţi, FQ nu poate fi implementată exact. O primă idee pentru implementarea FQ la nivel de pachet ar fi să utilizăm din nou round-robin. Din păcate, un moment de reflexie ne spune că această soluţie nu este cea mai potrivită. Următorul exemplu ilustrează problema: dacă avem doua fluxuri, unul care transmite pachete de cîte 1000 octeţi, iar celălalt care transmite pachete de cîte 100 octeţi, este uşor de văzut ca aplicînd round robin la nivel de pachet are drept rezultat alocarea unei capacităţi de 10 ori mai mare primului flux! De aceea, în practică, pentru implementarea FQ-ului se utilizează algoritmi mai sofisticaţi.
Un exemplu de astfel de algoritm este următorul: pentru fiecare pachet se calculează momentul de timp la care ultimul bit al acestuia ar urma să fie transmis într-un ruter ideal, în care traficul este transmis bit cu bit; apoi pachetele sunt transmise în ordinea crescătoare a acestor timpi.
Descrierea de mai sus sugerează principalul dezavantaj al disciplinei FQ: complexitatea. În esenţă ruterul trebuie sa ţină evidenţa pentru fiecare flux şi sa execute următoarele operaţii:
Deci, pe de o parte, avem FIFO, care este foarte uşor de implementat la viteze mari, dar nu asigură o alocare echitabilă a capacităţii, iar pe de alta parte avem FQ care asigură o distribuţie echitabilă a capacităţii, dar este mult mai complex de implementat. O întrebare firească este atunci dacă există o cale de mijloc, care sa îmbine simplitatea FIFO cu serviciul asigurat de FQ. Vom vedea o astfel de soluţie mai jos, dar înainte vom studia mai atent care este trăsătura indezirabilă a algoritmului FQ.
Care este diferenţa dintre FIFO şi FQ care face FQ mai dificil de implementat? Dacă încercăm să scriem un program care să le implementeze, vom observa că FIFO manipulează structuri de date extrem de simple: de fapt o singură structură de date, care este o listă înlănţuită de pachete, stocate în ordinea sosirii. Listei i se adaugă pachete la coadă şi i se iau pachete de la cap. Aceste operaţii se pot implementa în cîteva linii de cod, deci se pot executa extrem de rapid.
Pe de altă parte, dacă studiem FQ, o să notăm faptul că ruterul trebuie să facă contabilitate pentru fiecare flux care îl traversează. Asta înseamnă o sumedenie de lucruri destul de neplăcute:
Chiar dacă operaţiile acestea sunt relativ simple, structurile manipulate sunt foarte complicate; avem de-a face cu cozi care cresc independent, deci ne trebuie un alocator de memorie destul de sofisticat3, care trebuie invocat la fiecare pachet venit sau plecat. În plus, numărul de structuri de date manipulate depinde de numărul de fluxuri din ruter.
Probleme extrem de greu de rezolvat apar dacă un calculator cu o conexiune deschisă cade: el nu va trimite niciodată semnalul de închiderea conexiunii, deci ruterul va păstra o coadă care teoretic nu mai dispare niciodată. Vom vedea într-un alt articol cum se rezolvă genul ăsta de neplăceri, folosind o tehnică numită soft state.
Cît de mare este numărul de fluxuri dintr-un ruter care operează în centrul reţelei? Informaţii de la MCI, care este unul din cei mai mari operatori de reţea din Statele Unite, arată că numărul de fluxuri active simultan într-un ruter de mare capacitate se poate apropia de un milion!
Fiecare pachet venit trebuie deci clasificat într-unul din aproape un milion de fluxuri! Asta înseamnă, chiar cu algoritmi inteligenţi, o prelucrare substanţială pentru fiecare pachet venit. Asta este virtual imposibil pentru un ruter care deserveşte mai multe fluxuri de sute de megabiţi pe secundă4: pur şi simplu nu are destul timp pentru a prelucra pachetele!
Aceasta este diferenţa principală în ceea ce priveşte posibilitatea de a realiza FIFO şi FQ: FQ trebuie să facă din ce în ce mai multe operaţii, dacă numărul de fluxuri care traversează ruterul creşte. Operaţia lui FIFO pe de altă parte este aceeaşi, independent de cîte fluxuri avem.
Internetul este unul dintre cele mai mari sisteme construite vreodată de om (şi în viitor va deveni probabil cel mai mare); ca atare dimensiunile cu care trebuie operat sunt uriaşe în multe circumstanţe (de pildă un milion de fluxuri). Din cauza asta algoritmii executaţi de rutere trebuie să fie eficienţi atît la un număr mic de conexiuni/pachete, cît şi la valori astronomice. Această proprietate a unui algoritm se numeşte scalabilitate: capacitatea de a funcţiona eficient la valori foarte variate ale încărcăturii de date prelucrate.
Dacă un cercetător propune pentru managementul Internetului un algoritm care nu este scalabil, poate să fie absolut sigur că acel algoritm nu va fi folosit niciodată în afara unor sisteme mici, experimentale. Din cauza asta FQ nu este un algoritm practic; ne trebuie o alternativă.
Aşa cum am văzut, complexitatea algoritmului FQ se datorează în principal faptului că ruterul trebuie să menţină starea fiecărui flux. O schemă care să reducă în mod semnificativ complexitatea algoritmului FQ trebuie deci să reducă sau să elimine într-un mod sau altul această stare. Problema este că, dacă eliminăm pur şi simplu starea unui flux, nu mai este posibil să ``protejăm'' acel flux atunci cînd linia este congestionată. Suntem confruntaţi cu următoarea dilemă: pe de o parte dorim să eliminăm starea pentru a reduce complexitatea, dar pe de altă parte avem nevoie de această stare pentru a asigura protecţia fluxurilor.
Soluţia se bazează pe o idee foarte simplă: în loc să menţinem starea în rutere, o punem în pachete! Fiecare pachet oricum trebuie prelucrat de fiecare ruter, deci complexitatea procesării creşte doar cu un factor constant (iar nu cu un factor depinzînd de numărul de fluxuri). Algoritmul general arată atunci în felul următor:
În acest mod un nod interior nu are nevoie să menţină starea pentru fiecare flux, ceea ce face posibilă implementarea eficientă a algoritmului. Pe de altă parte, sursele sau nodurile de la marginea reţelei, care pun starea în pachete, trebuie să menţină stare pentru fiecare flux, pentru a eticheta corect pachetele. Din fericire, aceste noduri suportă un trafic mult mai mic decît nodurile interioare, şi în consecinţă nu ridică probleme de scalabilitate. Aceasta soluţie ``împinge'' starea din nodurile interioare la marginea reţelei şi apoi foloseşte pachetele pentru a transmite această stare.
În continuare descriem pe scurt un algoritm, numit Core-Stateless Fair Queueing (CSFQ), care implementează FQ în cadrul arhitecturii prezentate mai sus. ``Core-stateless'' înseamnă că ruterele din ``miezul'' reţelei nu menţin nici un fel de informaţii despre starea conexiunilor. Pentru a defini algoritmul trebuie să precizăm:
În CSFQ, starea înscrisă în pachete reprezintă rata fluxului; sursa sau primul nod din reţea calculează dinamic rata fiecărui flux şi o pune în pachetele acestuia. Nodurile interioare calculează pe baza traficului primit şi a celui transmis rata echitabilă care trebuie sa fie alocată fiecărui flux. Intuitiv, această este rata maximă care ar fi alocată unui flux de algoritmul FQ la ruterul respectiv (în exemplul dat mai sus, cu două conexiuni pe o linie de 1 Mbps, rata echitabilă era de 0.5 Mbps). Din lipsă de spaţiu nu prezentăm amănuntele calculării acestei rate. Cititorul interesat poate găsi detaliile la http://www.cs.cmu.edu/~istoica/csfq. În continuare vom prezenta numai operaţia executată de un ruter interior la primirea unui pachet.
Ne vom concentra asupra unei singure ieşiri din ruter; pentru fiecare ieşire vom menţine o altă valoare a ratei echitabile.
Să ne uităm la un ruter pentru care rata echitabilă este rb. Această rată depinde numai de numărul de fluxuri şi de capacitatea canalului de ieşire. Să zicem că acest ruter primeşte un pachet în care este înscrisă rata r. Atunci ruterul transmite pachetul cu probabilitatea P = max(1, rb/r) şi îl ``aruncă'' cu probabilitatea 1 - P. Se poate arăta ca aceasta operaţie foarte simplă duce la o buna aproximare a algoritmului FQ. Intuitiv, aceasta poate fi văzut în următorul exemplu didactic:
Să presupunem că avem un flux cu pachete de lungime egală şi cu o rată constantă r > rb, unde valoarea r este înscrisă în fiecare pachet de ruterele de la margine. În acest caz P = rb/r. Drept urmare, din n pachete vor fi transmise în medie numai n rb / r pachete. Deoarece fiecare pachet are aceeaşi lungime, rata fluxului se va reduce în medie cu rb / r, ceea ce înseamnă ca rata finală va fi r x rb / r = rb. În acest mod, fluxului îi este alocată probabilistic o rată de cel mult rb, rată care este egală cu rata echitabilă (adică cea alocată fluxului dacă FQ ar fi fost folosit)! În final, după ce aruncă din pachete, ruterul schimbă rata înscrisă în fiecare pachet cu rb. Informaţia din pachet rămîne astfel consistentă cu noua rată a fluxului după ce străbate ruterul congestionat.
Astfel, CSFQ este capabil să asigure o bună aproximare a algoritmului FQ la nodurile interioare, fără a menţine starea fluxurilor. În fapt, complexitatea acestui algoritm la nodurile interioare este apropiată de cea a algoritmului FIFO. În concluzie, CSFQ reuşeşte să îmbine simplitatea FIFO cu funcţionalitatea algoritmului FQ.
Figura 3 arată pentru comparaţi valorile fluxului obţinute cu un simulator, în exact condiţiile din experimentul anterior cu TCP.
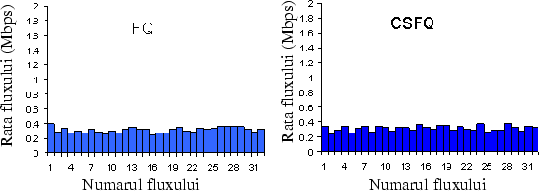 |
Există o grămadă de alte detalii despre funcţionarea CSFQ, inclusiv simulări detaliate şi estimări analitice ale calităţii sale; acestea sunt toate descrise pe larg în articolul ``Core Stateless Fair Queueing: Achieving Approximately Fair Bandwidth Allocations in High Speed Networks'', de Ion Stoica, Scott Shenker şi Hui Zhang, prezentat în 1998 la conferinţa SIGCOMM, a cărui copie este disponibilă din pagina de web a lui Ion.
În acest articol ilustrăm modul în care se poate proiecta o soluţie pentru rezolvarea unei probleme specifice în Internet. Articolul însă aparent bate mult timp cîmpii, pentru că trebuie să construim o serie de concepte. Iată aici o vedere de ansamblu a schemei articolului;
Cred că e cinstit să stăvilim aici fluxul de informaţii pe care le transportă acest articol. Vom reveni.