Selection Benchmark
Figure 8 shows the performance achieved for the selection benchmark. The ordering of the results is the same as for the line-fit benchmark: for small problem sizes, the VCODE interpreter is fastest, followed by the JIT compiler, native methods, and finally the JDK; for large problem sizes, the ordering of the JIT compiler and the native methods implementation is reversed. However, the shapes of the curves are different than for the line-fit benchmark, reflecting the fact that the selection benchmark spends less time in straight-line code than line-fit, and places more emphasis on recursion and dynamic memory use. In particular, the performance curves of the JIT compiler and the native methods implementation cross at a larger problem size, because there is more work going on in the Java virtual machine (where the JIT compiler is faster) and less in the vector methods (where the native methods are faster).
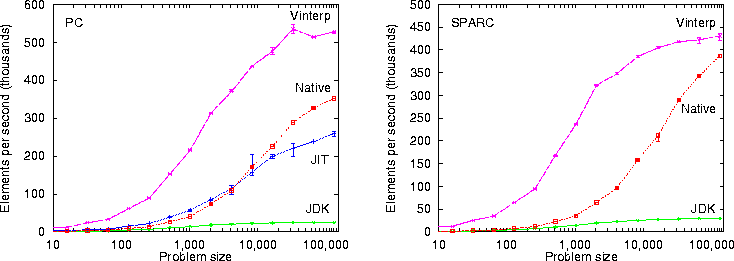
Figure 8: Performance of NESL selection benchmark using different intermediate language implementations on a 120 MHz 486 PC (left) and a SPARCstation 5/85 (right).