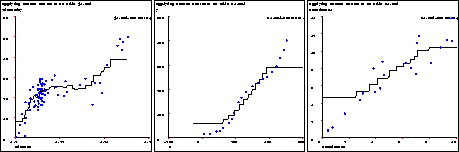
Figure 4: 9 nearest neighbor on some one dimensional data sets
By now, you may have realized that the nearest neighbor method described earlier is a kind of memory based learning. Look back at the graphs produced with the nearest neighbor model (fig. 3). This is also an opportunity to demonstrate another feature of Vizier. You can see the graphs from past pages of Vizier output using the following commands:
View -> Previous Page
-> Next Page
The most distressing aspect of these graphs is that they fit noise, which yields less accurate predictions. One way to counteract this problem is to consider more than one nearest neighbor, which is called k-nearest neighbors. The prediction is the average output of the k points nearest to the query. We can use Vizier to see what happens when we try k = 9 on our three one dimensional data sets.
Edit -> Metacode -> Regression A: Averaging
Localness 0: No Local Weighting
Neighbors 1: T+9 Nearest
File -> Open -> j1.mbl
Model -> Graph -> Graph
File -> Open -> k1.mbl
Model -> Graph -> Graph
File -> Open -> a1.mbl
Model -> Graph -> Graph
The resulting graphs can be seen in fig. 4. The graph of j1.mbl shows that 9 nearest neighbor has managed to average out the noise in the function and produce a better fit than 1 nearest neighbor. However, 9 nearest neighbor made the fit to k1.mbl worse. There was no noise in that data to begin with, and the averaging ended up smearing out some of the structure in the data. It is obvious that no single value of k works best for all data sets. On a1.mbl the noise is taken care of, but the other inadequacies of k-nearest neighbor are apparent. There is still no useful gradient information in the function, and the fit near the boundaries of the data at the left and right side of the graph is poor. In the next two sections we will see what can be done to remedy those problems, but even when using those remedies we may still want to choose some non-zero number of nearest neighbors to get the best fit to data.