


With the mixtures of Gaussians model, there are three design parameters that must be considered --- the number of Gaussians, their initial placement, and the number of iterations of the EM algorithm. We set these parameters by optimizing them on the learner using random examples, then used the same settings on the learner using the variance-minimization criterion. Parameters were set as follows: Models with fewer Gaussians have the obvious advantage of requiring less storage space and computation. Intuitively, a small model should also have the advantage of avoiding overfitting, which is thought to occur in systems with extraneous parameters. Empirically, as we increased the number of Gaussians, generalization improved monotonically with diminishing returns (for a fixed training set size and number of EM iterations). The test error of the larger models generally matched that of the smaller models on small training sets (where overfitting would be a concern), and continued to decrease on large training sets where the smaller networks ``bottomed out.'' We therefore preferred the larger mixtures, and report here our results with mixtures of 60 Gaussians. We selected initial placement of the Gaussians randomly, chosen uniformly from the smallest hypercube containing all current training examples. We arbitrarily chose the identity matrix as an initial covariance matrix. The learner was surprisingly sensitive to the number of EM iterations. We examined a range of 5 to 40 iterations of the EM algorithm per step. Small numbers of iterations (5-10) appear insufficent to allow convergence with large training sets, while large numbers of iterations (30-40) degraded performance on small training sets. An ideal training regime would employ some form of regularization, or would examine the degree of change between iterations to detect convergence; in our experiments, however, we settled on a fixed regime of 20 iterations per step.
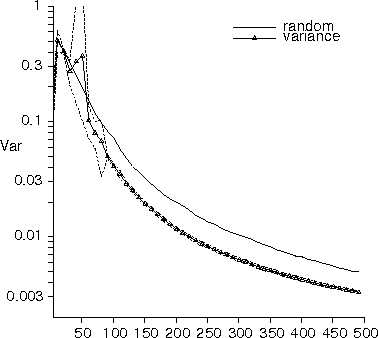

Figure 5: Variance and MSE learning curves for mixture
of 60 Gaussians trained on the Arm2D domain. Dotted lines denote
standard error for average of 10 runs, each started with one initial
random example.
Figure 5 plots the variance and MSE learning curves for a
mixture of 60 Gaussians trained on the Arm2D domain with 1% input
noise added. The estimated model variance using the
variance-minimizing criterion is significantly better than that of the
learner selecting data at random. The mean squared error, however,
exhibits even greater improvement, with an error that is consistently
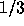 that of the randomly sampling learner.
that of the randomly sampling learner.