Vizier is designed mainly for regression problems (predicting continuous valued outputs), but also does well on classification problems. In this section we'll see how it does classification and learn about some of the other features of Vizier. First, we'll look at the format and see how it can be changed. The format specifies which attributes in a data set are used for making predictions (the inputs), which are being predicted (the outputs), and which are unused. It is also specifies whether to do classification or regression.
File -> Open -> iris.mbl
Edit -> Format -> sepal_length -> Unused
sepal_width -> Unused
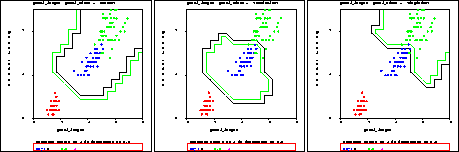
Figure 15: Classification on the iris data set. a) the setosa decision boundary, b) the versicolor decision boundary, c) the virginica decision boundary
While editing the format, note the check box specifying that this is a classification problem. The check was turned on automatically because the data file indicated that it contained class data. You may refer to the help on data file formats for more information on how this is done. The extent of each attribute is also available for editing in the format window. By default it is set near the high and low value of that attribute in the data set. The extent is used to scale the data for internal computations. Although it may be modified, in practice it is almost never useful or necessary to do so.
Edit -> Metacode -> Regression A: Average
Localness 2: Ultra local
Model -> Graph -> Dimensions -> 2
x attribute -> petal_length
y attribute -> petal_width
z attribute -> setosa?
Graph
The resulting plot shows all the data points color coded according to their true class given in the data set. The contour lines show the decision boundary between the class setosa and the other classes. Often, it is desirable to see all the decision boundaries.
Model -> Graph -> z attribute -> [all outputs]
Graph
These plots are shown in fig. 15. Together they show the decision boundaries for all the classes. As with regression, the selection of an appropriate metacode is important for achieving accurate predictions. Experiment with other metacodes to see how they affect the decision boundaries for this data set.