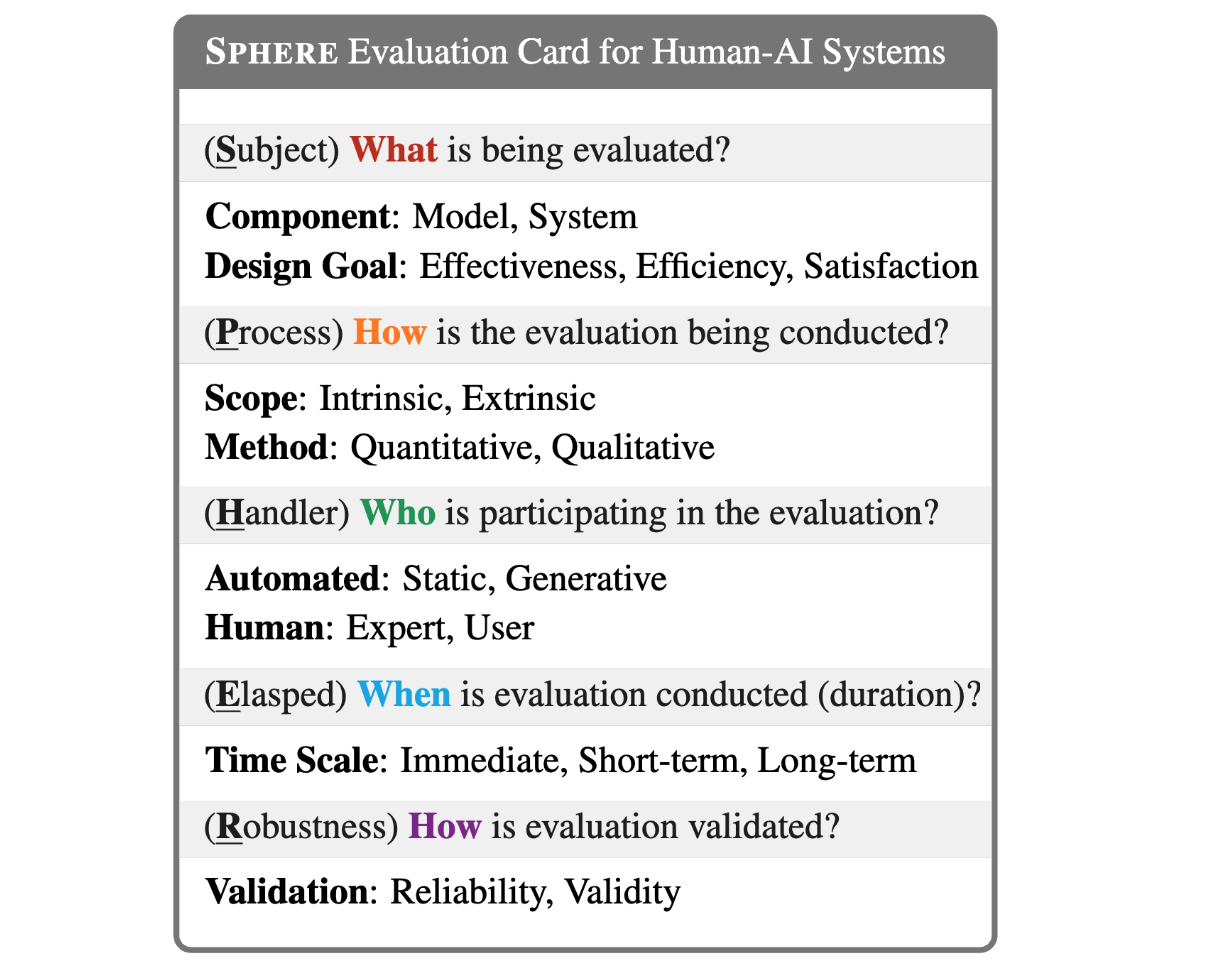
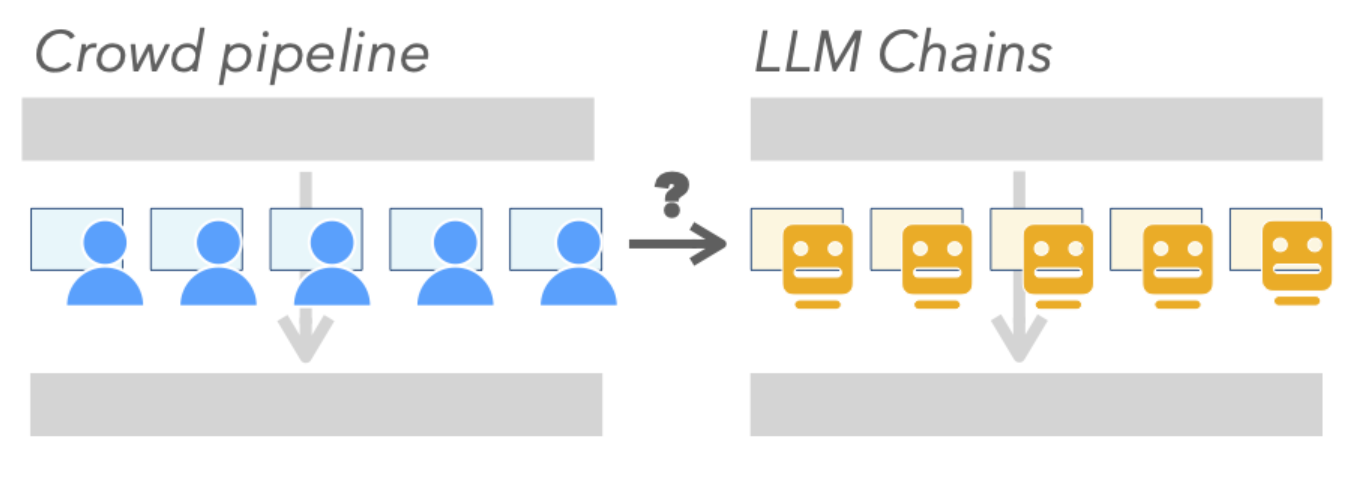
Real-world AI Evaluation
We askWhat can general-purpose models do?
We doReplicate diverse human-subject experiments with general-purpose models.
I am trained at the University of Washington) to be an HCI+NLP researcher. I study how humans (AI experts, lay users, domain experts) interact with (debug, audit, collaborate) AI systems.
Most recently, I work on:Design practical AIs that can help users in complex tasks, where users are not oracle, and not static.