In order to determine which part of the input image the network uses to decide whether the input is a face, we performed a sensitivity analysis using the method of [2]. We collected a positive test set based on the training database of face images, but with different randomized scales, translations, and rotations than were used for training. The negative test set was built from a set of negative examples collected during the training of an earlier version of the system. Each of the 20x20 pixel input images was divided into 100 2x2 pixel subimages. For each subimage in turn, we went through the test set, replacing that subimage with random noise, and tested the neural network. The resulting sum of squared errors made by the network is an indication of how important that portion of the image is for the detection task. Plots of the error rates for two networks we developed are shown in Figure 9. Network 1 uses two sets of the hidden units illustrated in Figure 1, while Network 2 uses three sets.
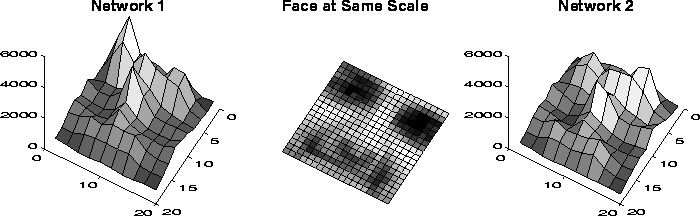
Figure:
Error rates (vertical axis) on a small test resulting from adding
noise to various portions of the input image (horizontal plane), for
two networks. Network 1 has two copies of the hidden units shown in
Figure 1 (a total of 58 hidden units and 2905
connections), while Network 2 has three copies (a total of 78 hidden
units and 4357 connections).
The networks rely most heavily on the eyes, then on the nose, and then on the mouth (Figure 9). Anecdotally, we have seen this behavior on several real test images. Even in cases in which only one eye is visible, detection of a face is possible, though less reliable, than when the entire face is visible. The system is less sensitive to the occlusion of features such as the nose or mouth.