The previous sections dealt with a simple robot navigation problem.
This section demonstrates that these features also exist in a quite
different domain, that of a two degrees of freedom robot arm, as shown
in Figure 11. The shoulder joint can achieve any
angle between ![]() radians, the elbow joint any angle between
radians, the elbow joint any angle between
![]() radians, zero is indicated by the arrows. If the arm is
straight and the shoulder joint rotated, the elbow joint will describe
the inner dotted circle, the hand the outer dotted circle. There are
eight actions, small rotations either clockwise or anti-clockwise for
each joint separately or together. The aim is to learn to move the
arm efficiently from any initial position until the hand reaches the
goal on the perimeter of the arm's work space.
radians, zero is indicated by the arrows. If the arm is
straight and the shoulder joint rotated, the elbow joint will describe
the inner dotted circle, the hand the outer dotted circle. There are
eight actions, small rotations either clockwise or anti-clockwise for
each joint separately or together. The aim is to learn to move the
arm efficiently from any initial position until the hand reaches the
goal on the perimeter of the arm's work space.
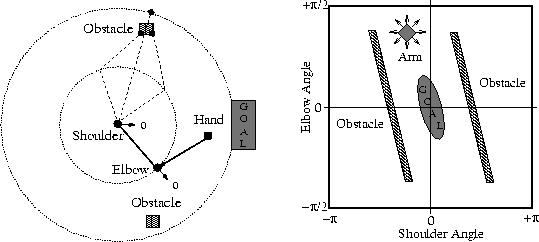
The state space, for the purposes of reinforcement learning, is the configuration space for the arm, sometimes called the joint space (see Figure 12). The x-axis is the angle of the shoulder joint, the y-axis the elbow joint. The eight actions when mapped to actions in the configuration space become much like the actions in the robot navigation problem, as shown by the shaded diamond (labeled Arm) in Figure 12. To map an obstacle in the work space to the configuration space, one must find all pairs of shoulder and elbow angles blocked by the obstacle. The obstacles in this space become elongated to form barriers much like the walls in the experiments of the previous sections. If this is not clear, imagine straightening the arm in the work space and rotating it such that it intersects one of the obstacles, the middle dotted line in Figure 11. The arm can then be rotated at the shoulder joint with a roughly linearly proportional rotation in the elbow joint, but in the opposite direction, such as to keep it intersecting the obstacle. This produces the ``wall'' in the configuration space. This linearity holds only for small objects not too far from the perimeter of the work space. More complex, larger objects, would result in more complex shapes in the configuration space. At the moment the feature extraction method is limited to these simpler shapes, this will be discussed further in Section 6.
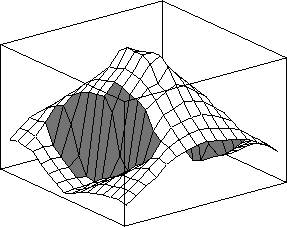
The reinforcement learning function produced by this problem is shown in Figure 13. As before the features are shaded for clarity. The large gradient associated with the obstacle on the left hand side of the configuration space can be clearly seen. There is a similar large gradient associated with the obstacle on the right hand side of the configuration space. Again, these features can be used to control the composition of functions if the goal is moved or for a different task in the same domain.