This section describes how to reduce the number of generated rules to a relatively small number of diverse rules. Reducing the rule set is desirable because expecting experts to evaluate a large set of rules is unfeasible, and second, experiments demonstrate that there are subsets of very similar rules which use almost the same attribute values and have similar prediction properties.
The weighted covering approach proposed for confirmation rule subset selection (Gamberger & Lavrac, 2000) defines diverse rules as those that cover diverse sets of target class examples. The approach, implemented in Algorithm RSS outlined in Figure 2, can not guarantee statistical independence of the selected rules, but it ensures the diversity of generated subsets.
Input to Algorithm RSS are the set of all target class examples P
and the set of rules S. Its output is a reduced set of rules SS,
![]() .
The user adjustable parameter number determines how
many rules will be selected for inclusion in output set SS. For
every example
.
The user adjustable parameter number determines how
many rules will be selected for inclusion in output set SS. For
every example ![]() there is a counter c(e). Initially, the
output set of selected rules is empty (step 1) and all counter values
are set to 1 (step 2). Next, in each iteration of the loop (steps 3 to
8), one rule is added to the output set (step 7). From set S, the
rule with the highest weight value is selected. For each rule,
weight is computed so that 1/c(e) values are added for all target
class examples covered by this rule (step 4). After rule selection,
the rule is eliminated from set S (step 6) and c(e) values for all
target class examples covered by the selected rule are incremented by
1 (step 5). This is the central part of the algorithm which ensures
that in the first iteration all target class examples contribute the
same value 1/c(e) = 1 to the weight, while in the following
iterations the contributions of examples are inverse proportional to
their coverage by previously selected rules. In this way the examples
already covered by one or more selected rules decrease their weights
while rules covering many yet uncovered target class examples whose
weights have not been decreased will have a greater chance to be
selected in the following iterations.
there is a counter c(e). Initially, the
output set of selected rules is empty (step 1) and all counter values
are set to 1 (step 2). Next, in each iteration of the loop (steps 3 to
8), one rule is added to the output set (step 7). From set S, the
rule with the highest weight value is selected. For each rule,
weight is computed so that 1/c(e) values are added for all target
class examples covered by this rule (step 4). After rule selection,
the rule is eliminated from set S (step 6) and c(e) values for all
target class examples covered by the selected rule are incremented by
1 (step 5). This is the central part of the algorithm which ensures
that in the first iteration all target class examples contribute the
same value 1/c(e) = 1 to the weight, while in the following
iterations the contributions of examples are inverse proportional to
their coverage by previously selected rules. In this way the examples
already covered by one or more selected rules decrease their weights
while rules covering many yet uncovered target class examples whose
weights have not been decreased will have a greater chance to be
selected in the following iterations.
In the publicly available Data Mining Server, RSS is
implemented in an outer loop for SD.
Figure 3 gives the pseudo code of algorithm DMS. In its
inner loop, DMS calls SD and selects from its beam the single best
rule to be included into the output set SS. To enable SD to induce a
different solution at each iteration, example weights c(e) are
introduced and used in the quality measure which is defined as
follows:
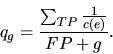
The main reason for the described implementation is to ensure the
diversity of induced subgroups even though, because of the short
execution time limit on the publicly available server, a low
![]() parameter value in Algorithm SD had to be set (the
default value is 20). Despite the favorable diversity of rules
achieved through Algorithm DMS, the approach has also some drawbacks.
The first drawback is that the same rule can be detected in different
iterations of Algorithm DMS, despite of the changes in the c(e)
values. The more important drawback is that heuristic search with a
small
parameter value in Algorithm SD had to be set (the
default value is 20). Despite the favorable diversity of rules
achieved through Algorithm DMS, the approach has also some drawbacks.
The first drawback is that the same rule can be detected in different
iterations of Algorithm DMS, despite of the changes in the c(e)
values. The more important drawback is that heuristic search with a
small ![]() value may prevent the detection of some good
quality subgroups. Therefore during exploratory applications, applying
a single SD execution with a large
value may prevent the detection of some good
quality subgroups. Therefore during exploratory applications, applying
a single SD execution with a large ![]() followed by a single
run of RSS appears to be a better approach.
followed by a single
run of RSS appears to be a better approach.

