|
| > loadWorld('coin') |
load coin NMRDP |
|
> preprocess('sPltl') |
PLTLSTR preprocessing |
|
> startCPUtimer |
|
|
> spudd(0.99, 0.0001) |
solve MDP with SPUDD
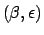 |
|
> stopCPUtimer |
|
|
> readCPUtimer |
report solving time |
|
1.22000 |
|
|
> iterationCount |
report number of iterations |
|
1277 |
|
|
> displayDot(valueToDot) |
display ADD of value function |
![\includegraphics[height=0.17\textheight]{figures/value}](img373.png) |
|
> displayDot(policyToDot) |
display policy |
![\includegraphics[height=0.1\textheight]{figures/policy}](img374.png) |
|
> preprocess('mPltl') |
PLTLMIN preprocessing |
|
> expand |
completely expand MDP |
|
> domainStateSize |
report MDP size |
|
6 |
|
|
> printDomain ("") | 'show-domain.rb' |
display postcript rendering of MDP |
![\includegraphics[height=0.28\textheight]{figures/domain}](img375.png) |
|
> valIt(0.99, 0.0001) |
solve MDP with VI
|
|
> iterationCount |
report number of iterations |
|
1277 |
|
|
> getPolicy |
output policy (textual) |
|
...
|
|
|
