The common framework underlying NMRDPP takes advantage of the fact
that NMRDP solution methods can, in general, be divided into the
distinct phases of preprocessing, expansion, and solving.
The first two
are optional.
For PLTLSIM, preprocessing simply computes the set
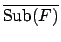 of subformulae of the reward formulae. For PLTLMIN, it
also includes computing the labels
of subformulae of the reward formulae. For PLTLMIN, it
also includes computing the labels  for each state
for each state  . For
PLTLSTR, preprocessing involves computing the set
. For
PLTLSTR, preprocessing involves computing the set  of temporal
variables as well as the ADDs for their dynamics and for the
rewards. FLTL does not require any preprocessing.
Expansion is the optional generation of the entire equivalent
MDP prior to solving. Whether or not off-line expansion is sensible
depends on the MDP solution method used. If state-based value or
policy iteration is used, then the MDP needs to be expanded
anyway. If, on the other hand, an anytime search algorithm or
structured method is used, it is definitely a bad idea. In our
experiments, we often used expansion solely for the purpose of
measuring the size of the generated MDP.
Solving the MDP can be done using a number of
methods. Currently, NMRDPP provides implementations of classical
dynamic programming methods, namely state-based value and policy
iteration [32], of heuristic search methods: state-based
LAO* [28] using either value or policy
iteration as a subroutine, and of one structured method, namely SPUDD
[29]. Prime candidates for future developments are
(L)RTDP [9], symbolic LAO* [21],
and symbolic RTDP [22].
Sylvie Thiebaux
2006-01-20
of temporal
variables as well as the ADDs for their dynamics and for the
rewards. FLTL does not require any preprocessing.
Expansion is the optional generation of the entire equivalent
MDP prior to solving. Whether or not off-line expansion is sensible
depends on the MDP solution method used. If state-based value or
policy iteration is used, then the MDP needs to be expanded
anyway. If, on the other hand, an anytime search algorithm or
structured method is used, it is definitely a bad idea. In our
experiments, we often used expansion solely for the purpose of
measuring the size of the generated MDP.
Solving the MDP can be done using a number of
methods. Currently, NMRDPP provides implementations of classical
dynamic programming methods, namely state-based value and policy
iteration [32], of heuristic search methods: state-based
LAO* [28] using either value or policy
iteration as a subroutine, and of one structured method, namely SPUDD
[29]. Prime candidates for future developments are
(L)RTDP [9], symbolic LAO* [21],
and symbolic RTDP [22].
Sylvie Thiebaux
2006-01-20