This section compares iterative optimization strategies under two experimental conditions. In the first condition, a random ordering of observations is generated and hierarchically sorted. Each of the optimization strategies is then applied independently to the resultant hierarchical clustering. These experiments assume that the primary goal of clustering is to discover a single-level partitioning of the data that is of optimal quality. Thus, the objective function score of the first-level partition is taken as the most important dependent variable. An independent variable is the height of the initially-constructed clustering; this can effect the granularity of clusters that are used in hierarchical redistribution. A hierarchical clustering of height 2 corresponds to a single level partition of the data at depth 1 (the root is at depth 0), with leaves corresponding to individual observations at depth 2.
In addition to experiments on clusterings derived by sorting random initial orderings, each redistribution strategy was tested on exceptionally poor initial clusterings generated by nonrandom orderings. Just as `dissimilarity' orderings lead to good clusterings, `similarity' orderings lead to poor clusterings [Fisher et al., 1992]. Intuitively, a similarity ordering samples observations within the same region of the data description space before sampling observations from differing regions. The reordering procedure of Section 3.1 is easily modified to produce similarity orderings by ranking each set of siblings in a hierarchical clustering from least to most probable, and appending rather than interleaving observation lists from differing clusters as the algorithm pops up the recursive levels. A similarity ordering is produced by applying this procedure to an initial clustering produced by an earlier sort of a random ordering. Another clustering is then produced by sorting the similarity-ordered data, and the three iterative optimization strategies are applied independently. We do not advocate that one build clusterings from similarity orderings in practice, but experiments with such orderings better test the robustness of the various optimization strategies.
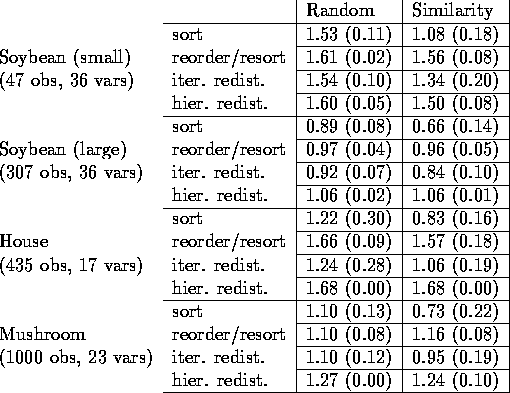
Table 2: Iterative optimization strategies with
initial clusterings generated from sorting random and similarity
ordered observations. Tree height is 2.
Averages and standard deviations of PU scores over 20 trials.
Table 2 shows the results of
experiments with random and similarity orderings of data from
four databases of the UCI repository. These results assume an initial clustering of height 2 (i.e., a top-level
partition + observations at leaves).
Each cell represents an average and standard deviation
over 20 trials. The first cell (labeled `sort') of each domain is the
mean PU scores initially obtained by sorting. Subsequent
rows under each domain reflect the mean scores obtained by
the reordering/resorting procedure of Section 3.1, iterative
redistribution of single observations described in Section 3.2,
and hierarchical redistribution described in Section 3.3.
These results assume an initial clustering of height 2 (i.e., a top-level
partition + observations at leaves).
Each cell represents an average and standard deviation
over 20 trials. The first cell (labeled `sort') of each domain is the
mean PU scores initially obtained by sorting. Subsequent
rows under each domain reflect the mean scores obtained by
the reordering/resorting procedure of Section 3.1, iterative
redistribution of single observations described in Section 3.2,
and hierarchical redistribution described in Section 3.3.
The main findings reflected in Table 2 are:
Note that with initial hierarchical clusterings of height 2, the only difference between iterative hierarchical redistribution and redistribution of single observations is that hierarchical redistribution considers `merging' clusters of the partition (by reclassifying one with respect to the others) prior to redistributing single observations during each pass through the hierarchy.
Section 3.3
suggested that the expected benefits of hierarchical redistribution
might be greater for deeper initial trees with more granular clusters.
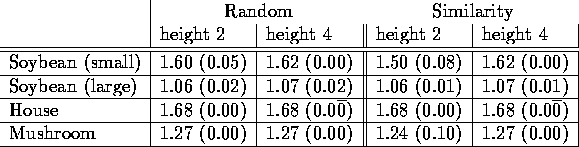
Table 3 shows results on the same domains and initial
orderings when tree height is 4 for hierarchical redistribution;
for the reader's convenience we also repeat the results from
Table 2
for hierarchical redistribution when tree height is 2. In moving from
height 2 to 4,
there is modest improvement in the small Soybean domain (particularly
under Similarity orderings),
and very slight improvement in the large Soybean domain
and the Mushroom domain under Similarity orderings.
While the improvements are very modest, moving to height 4 trees leads to near identical performance in the random and similarity ordering conditions. This suggests that hierarchical redistribution is able to effectively overcome the disadvantage of initially poor clusterings.
Table 3: Hierarchical redistribution with
initial clusterings generated from sorting random and similarity
ordered observations. Results are shown for
tree heights of 2 (copied from Table 2) and 4.
Averages and standard deviations of PU scores over 20 trials.
Experiments with reorder/resort and iterative distribution of single observations also were varied with respect to tree height (e.g., height 3). For each of these methods, the deepest set of clusters in the initial hierarchy above the leaves, was taken as the initial partition. Reordering/resorting scores remained roughly the same as the height 2 condition, but clusterings produced by single-observation redistribution had PU scores that were considerably worse than those given in Table 2.
We also recorded execution time for each method.
Table 4 shows the time required
for each method in seconds. In particular, for each domain,
Table 4 lists the mean time for initial
sorting, and the mean additional time for each optimization method.
Ironically, these experiments
demonstrate that even though hierarchical
redistribution `bottoms-out' in a single-observation form
of redistribution, the former is consistently faster than the
latter for trees of height 2 -- reclassifying a cluster simultaneously
moves a set of observations, which would otherwise have to be
repeatedly evaluated for redistribution individually with increased
time to stabilization.
Table 4: Time requirements (in seconds) of hierarchical sorting and
iterative optimization with
initial clusterings generated from sorting random and similarity
ordered observations. Tree height is 2.
Averages and standard deviations over 20 trials.
Table 4 assumes the tree constructed by initial sorting is bounded to height 2. Table 5 gives the time requirements of hierarchical sorting and hierarchical redistribution when the initial tree is bounded to height 4. As the tree gets deeper the cost of hierarchical redistribution grows substantially, and as our comparison of performance with height 2 and 4 trees in Table 3 suggests, there are drastically diminishing returns in terms of partition quality. Importantly, limited experiments with trees of height 2, 3, and 4 indicate that the cost of hierarchical redistribution is comparable to the cost of reorder/resort at greater tree heights and significantly less expensive than single-observation redistribution. It is difficult to give a cost analysis of hierarchical redistribution (and the other methods for that matter), since bounds on loop iterations probably depend on the nature of the objective function. Suffice it to say that the number of nodes that are subject to hierarchical redistribution in a tree covering n observations is bounded above by 2n-1; there may be up to n leaves and up to n-1 internal nodes given that each internal node has no less than 2 children.
Table 5: Time requirements (in seconds) of hierarchical sorting and
hierarchical redistribution with
initial clusterings generated from sorting random and similarity
ordered observations. Results are shown
for tree heights of 2 (copied from Table 4)
and 4.
Averages and standard deviations over 20 trials.
If iterative optimization is to occur in background, real-time response is not important, and cluster quality is paramount, then it is probably worth applying hierarchical redistribution to deeper trees; this is consistent with the philosophy behind such systems as AUTOCLASS and SNOB. For the domains examined here, however, it does not seem cost effective to optimize with trees of height greater than 4. Thus, we adopt a tree construction strategy that builds a hierarchical clustering three levels at a time (with hierarchical redistribution) in the experiments of Section 4.