In NESL the elements of a sequence can be any valid data item, including sequences. This rule permits the nesting of sequences to an arbitrary depth. A nested sequence can be written as
[[2, 1], [7,3,0], [4]]
![]()
NESL supplies a handful of functions for moving between levels of nesting. These include flatten, which takes a nested sequence and flattens it by one level. For example,
![]()
![]()

Table 2:
Routines with nested parallelism. Both the inner part
and the outer part can be executed in parallel.

Table 3:
Some divide and conquer algorithms.
Table 2 lists several examples of routines that could take advantage of nested parallelism. Nested parallelism also appears in most divide-and-conquer algorithms. A divide-and-conquer algorithm breaks the original data into smaller parts, applies the same algorithm on the subparts, and then merges the results. If the subproblems can be executed in parallel, as is often the case, the application of the subparts involves nested parallelism. Table 3 lists several examples.
As an example, consider how the function sum might be implemented,
/afs/cs/project/scandal/nesl/2.6/examples/preduce.cnesl
This code tests if the length of the input is one, and
returns the single element if it is. If the length is not one, it
uses bottop to split the sequence in two parts, and then applies
itself recursively to each part in parallel. When the parallel calls
return, the two results are extracted and added.![]() The code effectively creates a
tree of parallel calls which has depth
The code effectively creates a
tree of parallel calls which has depth ![]() , where n is the
length of a, and executes a total of n-1 calls to +.
, where n is the
length of a, and executes a total of n-1 calls to +.

Figure: An implementation of quicksort.
As another more involved example, consider a parallel variation of quicksort [6] (see Figure 2). When applied to a sequence s, this version splits the values into three subsets (the elements lesser, equal and greater than the pivot) and calls itself recursively on the lesser and greater subsets. To execute the two recursive calls, the lesser and greater sequences are concatenated into a nested sequence and qsort is applied over the two elements of the nested sequences in parallel. The final line extracts the two results of the recursive calls and appends them together with the equal elements in the correct order.
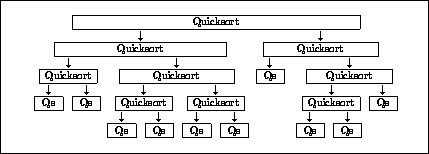
Figure 3: The quicksort algorithm.
Just using parallelism within each block yields a parallel
running time at least as great as the number of blocks ( ![]() ).
Just using parallelism from running the blocks in parallel yields a
parallel running time
at least as great as the largest block (
).
Just using parallelism from running the blocks in parallel yields a
parallel running time
at least as great as the largest block ( ![]() ).
By using both forms of parallelism the parallel running time can
be reduced to the depth of the tree (expected
).
By using both forms of parallelism the parallel running time can
be reduced to the depth of the tree (expected ![]() ).
).
The recursive invocation of qsort generates a tree of calls that
looks something like the tree shown in Figure 3. In this
diagram, taking advantage of parallelism within each block as well as
across the blocks is critical to getting a fast parallel algorithm.
If we were only to take advantage of the parallelism within each
quicksort to subselect the two sets (the parallelism within each
block), we would do well near the root and badly near the leaves
(there are n leaves which would be processed serially). Conversely,
if we were only to take advantage of the parallelism available by
running the invocations of quicksort in parallel (the parallelism
between blocks but not within a block), we would do well at the leaves
and badly at the root (it would take n time to process the root).
In both cases the parallel time complexity is ![]() rather than the
ideal
rather than the
ideal ![]() we can get using both forms (this is discussed in
Section 1.5).
we can get using both forms (this is discussed in
Section 1.5).