The ``Hopworld'' is a small domain designed to illustrate how ROUT
combines working backwards, adaptive sampling and function
approximation. The domain is an acyclic Markov chain of 13 states in
which each state has two equally probable successors: one step to the
right or two steps to the right. The transition rewards are such that
for each state ![]() . Our function approximator F makes
predictions by interpolating between values at every fourth state.
This is equivalent to using a linear approximator over the
four-element feature vector representation depicted in
Figure 8.
. Our function approximator F makes
predictions by interpolating between values at every fourth state.
This is equivalent to using a linear approximator over the
four-element feature vector representation depicted in
Figure 8.
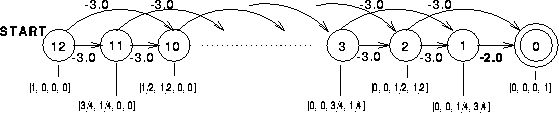
Figure 8: The Hopworld Markov chain. Each state is represented by a
four-element feature vector as shown. The function approximator
is linear.
In ROUT, we fit the training set using a batch least-squares fit. In
TD, the coefficients are updated using the delta rule with a
hand-tuned learning rate. The results are shown in
Table 1. ROUT's performance is efficient and predictable
on this contrived problem. At the start, HUNTFRONTIERSTATE finds F is
inconsistent and trains F(1) and F(2) to be -2 and -4,
respectively. Linear extrapolation then forces states 3 and 4 to be
correct. On the third iteration, F(5) is spotted as inconsistent
and added to the training set, and beneficial extrapolation continues.
By comparison, TD also has no trouble learning ![]() , but requires
many more evaluations. This is because TD trains blindly on all
transitions, not only the useful ones; and because its updates must be
done with a fairly small learning rate, since the domain is
stochastic. TD could be improved by an adaptive learning rate, but
even the most baroque scheme for adaptation would have a hard time
making the direct least-squares fits that ROUT is able to do.
, but requires
many more evaluations. This is because TD trains blindly on all
transitions, not only the useful ones; and because its updates must be
done with a fairly small learning rate, since the domain is
stochastic. TD could be improved by an adaptive learning rate, but
even the most baroque scheme for adaptation would have a hard time
making the direct least-squares fits that ROUT is able to do.