``Pig'' is a two-player children's dice game. Each player starts with a total score of zero, which is increased on each turn by dice rolling. The first to 100 wins. On her turn, a player accumulates a subtotal by repeatedly rolling a 6-sided die. If at any time she rolls a 1, however, she loses the subtotal and gets only 1 added to her total. Thus, before each roll, she must decide whether to (a) add her currently-accumulated subtotal to her permanent total and pass the turn to the other player; or (b) continue rolling, risking an unlucky 1.
Pig belongs to the class of symmetric, alternating, Markov games.
This means that the minimax-optimal value function can be formulated
as the unique solution to a system of generalized Bellman equations
[Littman and
Szepesvári1996] similar to Equation 4. The state
space, with two-player symmetry factored out, has 515,000
positions--large enough to be interesting, but small enough that
computing the exact ![]() is tractable.
is tractable.
For input to the function approximator, we represent states by their
natural 3-dimensional feature representation: X's total, O's total,
and X's current subtotal. The approximator is a standard MLP with two
hidden units. In ROUT, the network is retrained to convergence (at
most 1000 epochs) each time the training set is augmented. Note that
this extra cost of ROUT is not reflected in the results table, but for
practical applications, a far faster approximator than backprop would
be used with ROUT.
| # training | total eval- | RMS | RMS | Policy | ||
| Problem Method | samples | uations | Bellman | | Quality | |
| HOP | Discrete | 12 | 21 | 0 | 0 | -24 |
| ROUT | 4 | 158 | 0. | 0. | -24 | |
| TD(0) | 5000 | 10,000 | 0.03 | 0.1 | -24 | |
| TD(1) | 5000 | 10,000 | 0.03 | 0.1 | -24 | |
| PIG | Discrete | 515,000 | 3.6M | 0 | 0 | 0 |
| ROUT | 133 | 0.8M | 0.09 | 0.14 | -0.093 | |
|
| TD(0) + explore | 5 M | 30 M | 0.23 | 0.29 | -0.151 |
| TD(0.8) + explore | 9 M | 60 M | 0.23 | 0.33 | -0.228 | |
| TD(1) + explore | 6 M | 40 M | 0.22 | 0.30 | -0.264 | |
|
| TD(0) no explore | 8+ M | 50+ M | 0.12 | 0.54 | -0.717 |
| TD(0.8) no explore | 5 M | 35 M | 0.33 | 0.44 | -0.308 | |
| TD(1) no explore | 5 M | 30 M | 0.23 | 0.32 | -0.186 | |
| BAND | Discrete | 736,281 | 4 M | 0 | 0 | 0.682 |
| ROUT | 30 | 15,850 | 0.01 | 0.05 | 0.668 | |
| TD(0) | 150,000 | 900,000 | 0.07 | 0.14 | 0.666 | |
| TD(1) | 100,000 | 600,000 | 0.02 | 0.04 | 0.669 | |
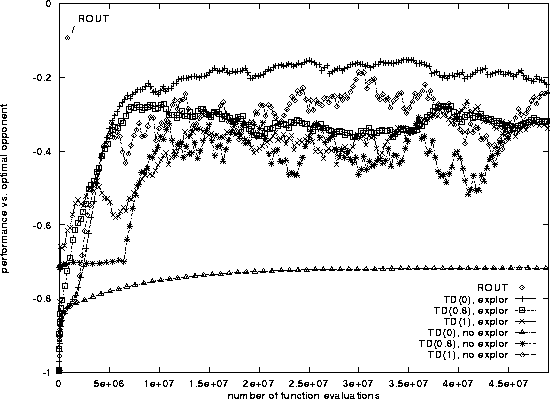
Figure 9: Performance of Pig policies learned by TD and ROUT. ROUT's
performance is marked by a single diamond at the top left of the
graph.
The Pig results are charted in Table 1 and graphed in Figure 9. The graph shows the learning curves for the best single trial of each of six classes of runs: TD(0), TD(0.8) and TD(1), with and without exploration. (The vertical axis measures performance in expected points per game against the minimax optimal player, where +1 point is awarded for a win and -1 for a loss.) The best TD run, TD(0) with exploration, required about 30 million evaluations to reach its best performance of about -0.15. By contrast, ROUT completed successfully in under 1 million evaluations, and performed at the significantly higher level of -0.09. ROUT's adaptively-generated training set contained only 133 states.