15-494 Cognitive Robotics
Partial Cube Detection
Ting-Yu Lan, tingyula@andrew.cmu.edu
Carrie Yuan, jiayiy@andrew.cmu.edu

Data Preprocessing and Augmentation
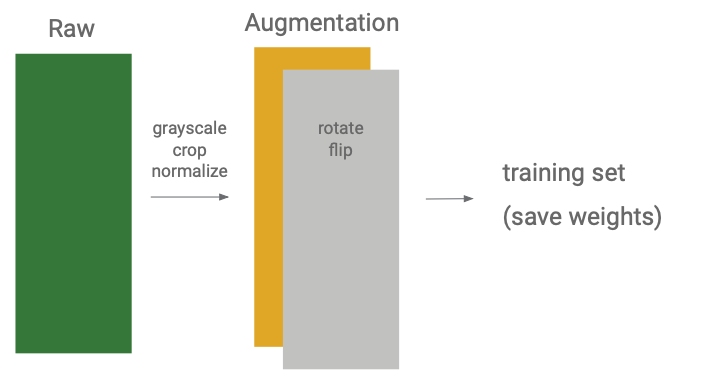
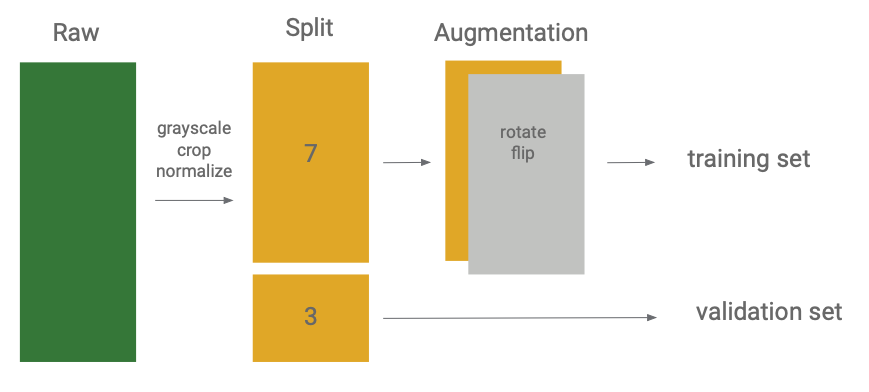
For all data, we transform them into grayscale image, crop them into half, and do normalization. Normalization is an important step for cozmo since the camera view is has low quality and it is not sensitive to light. Then, we split our dataset into ration of three to seven for validation and training, and do augmentation on training set.
For augmentation, we only do affine transform because in real cases, Cozmo would not distort images. Thus, we only need to recognize squared cube. Out augmentation including rotation, horizental flip, and vertical flip.
Neural Network
We use two convolution layer, with kernal size equals to 9 and 7 seperately, and connected it to two fully connected layers.
We choose binary cross entropy loss as our loss since this is a two classes classification problem. As to optimizer, we use SGD.

Get final training result
We modified our augmentation method, and network multiple times to get best velidation result. Then, we fixed these setting to train on whole dataset.