All three translations into an MDP (PLTLSIM, PLTLMIN, and
PLTLSTR) rely on the equivalence
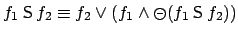 , with which we can
decompose temporal modalities into a requirement about the last state
, with which we can
decompose temporal modalities into a requirement about the last state
 of a sequence
of a sequence  , and a requirement about the
prefix
, and a requirement about the
prefix  of the sequence. More precisely, given state
of the sequence. More precisely, given state  and a formula
and a formula  , one can compute in2
, one can compute in2
 a new formula
a new formula
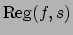 called the regression of through . Regression has the property
that, for
called the regression of through . Regression has the property
that, for  , is true of a finite sequence ending
with
, is true of a finite sequence ending
with 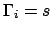 iff
is true of the prefix
. That is,
represents what must have been
true previously for to be true now.
iff
is true of the prefix
. That is,
represents what must have been
true previously for to be true now. 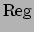 is defined as follows:
For instance, take a state in which
is defined as follows:
For instance, take a state in which  holds and
holds and  does not,
and take
does not,
and take
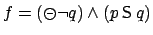 , meaning that
must have been false 1 step ago, but that it must have held at some
point in the past and that must have held since last did.
, meaning that
must have been false 1 step ago, but that it must have held at some
point in the past and that must have held since last did.
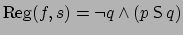 , that is, for to hold
now, then at the previous stage, had to be false and the
, that is, for to hold
now, then at the previous stage, had to be false and the
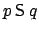 requirement still had to hold. When and are both false in
, then
requirement still had to hold. When and are both false in
, then
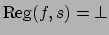 , indicating that cannot be
satisfied, regardless of what came earlier in the sequence.
For notational convenience, where
, indicating that cannot be
satisfied, regardless of what came earlier in the sequence.
For notational convenience, where  is a set of
formulae we write
is a set of
formulae we write 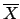 for
for
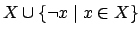 .
Now the translations exploit the PLTL representation of rewards as
follows. Each expanded state (e-state)
in the generated MDP can be seen as labelled
with a set
.
Now the translations exploit the PLTL representation of rewards as
follows. Each expanded state (e-state)
in the generated MDP can be seen as labelled
with a set
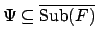 of subformulae of the reward
formulae in
of subformulae of the reward
formulae in  (and their negations). The
subformulae in
(and their negations). The
subformulae in 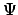 must be (1) true of the paths leading to the
e-state, and (2) sufficient to determine the current truth of all
reward formulae in , as this is needed to compute the current
reward. Ideally the s should also be (3) small enough to enable
just that, i.e. they should not contain subformulae which draw history
distinctions that are irrelevant to determining the reward at one
point or another. Note however that in the worst-case, the number of
distinctions needed, even in the minimal equivalent MDP, may be
exponential in
must be (1) true of the paths leading to the
e-state, and (2) sufficient to determine the current truth of all
reward formulae in , as this is needed to compute the current
reward. Ideally the s should also be (3) small enough to enable
just that, i.e. they should not contain subformulae which draw history
distinctions that are irrelevant to determining the reward at one
point or another. Note however that in the worst-case, the number of
distinctions needed, even in the minimal equivalent MDP, may be
exponential in  . This happens for instance with the formula
. This happens for instance with the formula
 , which requires
, which requires  additional bits of information
memorising the truth of over the last steps.
Sylvie Thiebaux
2006-01-20
additional bits of information
memorising the truth of over the last steps.
Sylvie Thiebaux
2006-01-20