For the choice of the 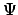 s,
Bacchus et al. [2] consider two
cases. In the simple case, which we call PLTLSIM, an MDP obeying
properties (1) and (2) is produced by simply labelling each e-state
with the set of all subformulae in
s,
Bacchus et al. [2] consider two
cases. In the simple case, which we call PLTLSIM, an MDP obeying
properties (1) and (2) is produced by simply labelling each e-state
with the set of all subformulae in
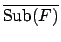 which are
true of the sequence leading to that e-state. This MDP is generated
forward, starting from the initial e-state labelled with
which are
true of the sequence leading to that e-state. This MDP is generated
forward, starting from the initial e-state labelled with 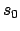 and
with the set
and
with the set
 of all subformulae which
are true of the sequence
of all subformulae which
are true of the sequence
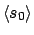 . The successors of any
e-state labelled by NMRDP state
. The successors of any
e-state labelled by NMRDP state  and subformula set are
generated as follows: each of them is labelled by a successor
and subformula set are
generated as follows: each of them is labelled by a successor  of
in the NMRDP and by the set of subformulae
of
in the NMRDP and by the set of subformulae
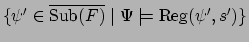 .
For instance, consider the NMRDP shown in Figure 3. The set
.
For instance, consider the NMRDP shown in Figure 3. The set
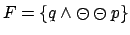 consists of a single reward
formula. The set
consists of all subformulae of this
reward formula, and their negations, that is
consists of a single reward
formula. The set
consists of all subformulae of this
reward formula, and their negations, that is
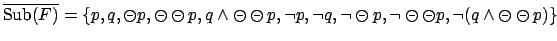 . The equivalent MDP produced by PLTLSIM is shown in
Figure 4.
. The equivalent MDP produced by PLTLSIM is shown in
Figure 4.
Figure 3:
Another Simple NMRDP
|
![$\textstyle \parbox{0.5\textwidth}{\includegraphics[height=0.18\textheight]{figures/pq}}$](img157.png)  |
Sylvie Thiebaux
2006-01-20