Case-based planning and explanation-based learning offer two differing approaches to improving the performance of a planner. Prior research [19] has analyzed their tradeoffs. The hybrid learning approach of DERSNLP+EBL is designed to alleviate the drawbacks associated with both pure case-based planning, and rule-based EBL. Prior to this work, EBL has been used to construct generalized search control rules which may be applied to each new problem-solving situation. These rules are matched at each choice point in the search process [5,30,31,24]. This approach is known to exhibit a utility problem since the rule base grows rapidly with increasing problem-solving experience and even a small number of rules may result in a high total match cost [30,38,19,9]. In contrast, the empirical results discussed here (see Table 4) indicate that DERSNLP+EBL has a low case retrieval and match cost.
To demonstrate how DERSNLP+EBL reduces match cost,
we conducted an empirical study which compared its performance with UCPOP+EBL,
a rule-based search control learning framework [24]. This framework
constructs reasons
for planning failures in a manner similar to DERSNLP+EBL.
However, its approach is similar to that of Minton [30]
in that it employs these explanations
in the construction of search control rules which are matched
at each node in the search tree.
The planners were tested
on a set of problems ranging from 2 to 6 goals which were
randomly generated from the blocks domain
shown in Figure 21.
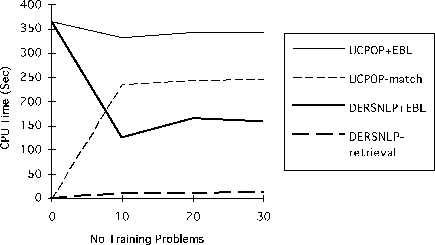
As illustrated in Figure 22, DERSNLP+EBL improved its performance after only 10 training problems solved. UCPOP+EBL failed to improve significantly. The reason is evident in UCPOP+EBL's match time (UCPOP-match) also graphed in Figure 22. For UCPOP+EBL, time spent in matching rules increases with training, wiping out any improvements that may have been gained through the use of those rules. When rules are matched at each choice point in the search tree, a small number of rules is sufficient to substantially increase the total match cost.
It is also possible to improve the performance of rule-based EBL by reducing the number of rules through the use of utility monitoring strategies [11], or by using a more sophisticated match algorithm [6]. For example, Doorenbos [6] employs an improved rule matcher based on the Rete algorithm. DERSNLP+EBL, on the other hand, aims at alleviating the utility problem by reducing the number of times rules are matched. Similar to rule-based EBL, its learning component is employed to generate rules. However, the rules that are generated govern the retrieval of the cases stored in the library. These are compiled into its indexing structure. DERSNLP+EBL exhibits low match cost by applying retrieval rules at only one point in the search process. Specifically, it retrieves cases only at the start of problem-solving. Each case represents a sequence of choices (a derivation path) thus providing global control as opposed to local. The results shown in Table 4 indicate that the cost of retrieving cases is significantly lower in comparison to time spent in problem-solving.